Setup: Explained

- Public Accessable IPv6, IPv4 tutorial fallback
- Load Wendelin via ShaCache
- Port forwarding via Socat
- Internally, Nexedi uses IPv4, front ends configured for IPv6
- Emulate server or data center in virtual machine
- Tutorial should be run on a laptop, server
- For the tutorial we setup 2 machines with 10 Virtual Machines each.
- IPv6:30001 access to QEMU-KVM IPv6:30001, after that NAT port forwarding to Localhost 20001 IPV4 internal
- Internally forwarded via SOCAT to slappart Jupyter/Zope...
Setup: Undressed

- "Naked" Machine with a KVM
- Can be hosted anywhere (OVH, AWS, ...) any architecture (ARM, Intel...)
- Public IPv4 and IPv6 (Res6t)
- SlapOS is architecture-independent, so any software that can be run on SlapOS could be run on any architecture.
- In case no IPv6 is available, we use re6st to create IPv6 adresses.
- Approach for Wendelin is the same, currently however we only test for Debian 8, 64bit machines.
Setup: Tutorial Preparation

- We use Slapos to deploy a cluster of VMs for the tutorial
- Using Two machines, 20 partitions
- Each partition with KVM Virtual Machine
- SlapOS = Hyperconvergent PaaS environment
- Wendelin uses SlapOS to be deployable on large scale
- Software recipe to create a cluster of 20 VMs on 2 machines: Coming soon
- Provider: Soyustart. Alternative Vifib.com, (40€/4€ per server/vm per month)
Setup: SlapOS "OUTSIDE" - Manage Access

- SlapOS manages partitions and installs virtual machine
- Port forwarding from Public IPv6 to KVM private IPv4
- SlapOS simplifies all access by always going through IPv6
- Machine has a public IPv4 (default) and IPv6 (default/res6st)
- SlapOS creates partitions with private IPv4, public IPv6
- Res6t makes all partitions accessible via public IPv6
- SlapOS recipe installs KVm on partition
- KVM has only 1 NAT interface to private IPv4 = no internet access by default
- SlapOS uses port-forwarding: IPv6:10022 to IPv4 0.0.0.0:22 same for :80,:443
- SlapOS "nat-rules" parameter allows additional ports to be forwarded
- We do this to simplify all access via IPv6, because if re6st is installed IPv6 will always be available
- Now we have public access to VM, no matter what is on the VM
- For tutorial we add rewrite rules to have IPv4 on top of this
Setup: SlapOS "INSIDE" - Manage Wendelin

- SlapOS is installed on KVM, too (used to manage cluster and VM)
- Shortcut: Wendelin download pre-compiled via ShaCache
- Shortcut: Socat to automatically bind, port forward KVM
- The VM can be anywhere, in our case it's on SlapOS managed cluster
- SlapOS is also used to manage the KVM itself
- SlapOS installed via Ansible script
- First install Slapproxy, normally manages a cluster, here only a single machine
- SlapOS components: Binaries and Instances (partitions, running services)
- Partitions are "mini-containers", services can be ERP5, Jupyter, MariaDB, etc
- Wendelin only exposes 2 services on IPv6: Apache and Jupyter
- Normal setup via webrunner and/or res6t will have public IPv6
- Normal setup set NAT-rules/tunnels between KVM and localhost by hand
- (SlapOS: use
<parameter id="nat-rules">20 80 443 20000 20001 20002 20003</parameter> )
- More info on VifiB/SlapOS forum
Todo: Access Virtual Machine
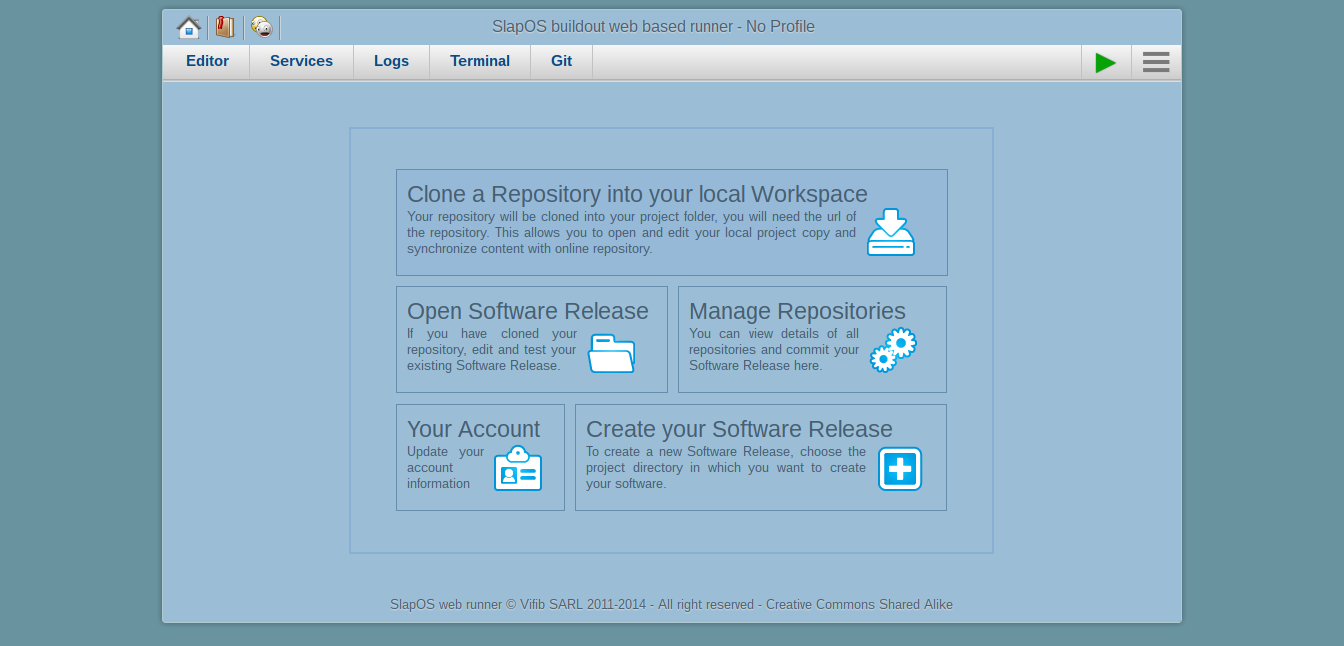
- Browser only tutorial (no IPv6)
- Go to
https://softinst67162.host.vifib.net/shell
- Don't click "Green Button" please.
- The webrunner is the interface used to work with SlapOS
- It includes file browser and editor, terminal, git and and logs section
- It allows to add/remove/configure different software products on your virtual machine
Todo: Access Terminal
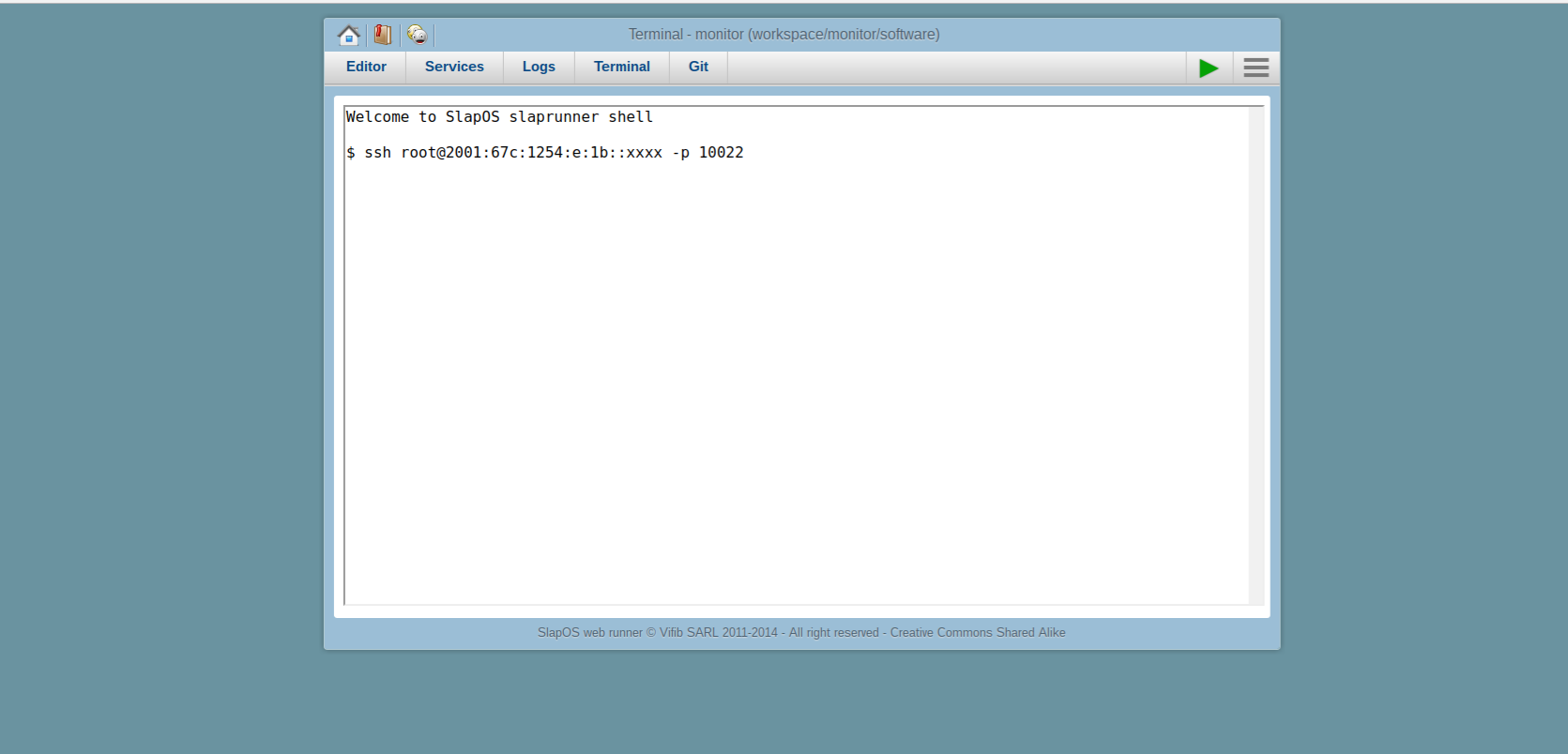
- Click the terminal tab
- Enter SSH/VNC provided (like
SSH slapos@2001:67c:1254:e:1b::XXXX -p 10022 )
- The webrunner is installed on your virtual machine. We will use it to install Wendelin
- Get your own resilient KVM through Vifib: Specifications, ViFib Homepage
- Getting started with Wendelin: Tutorial
Todo: Authenticate and install Wendelin
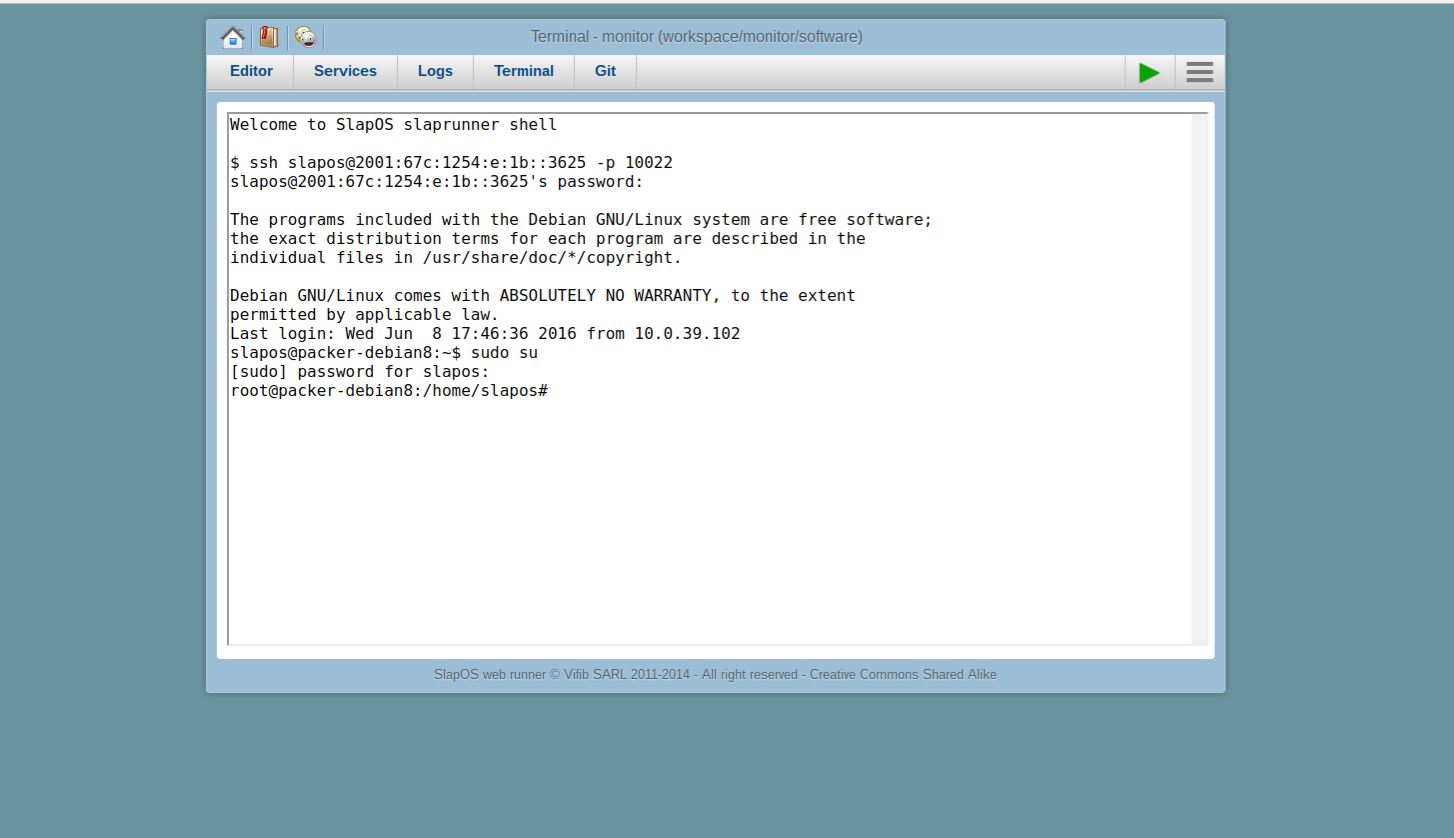
- Authenticate
- Switch to root
sudo -su , authenticate again, install via:
wget http://deploy.nexedi.cn/wendelin-standalone && bash wendelin-standalone
Todo: Monitor Installaton process
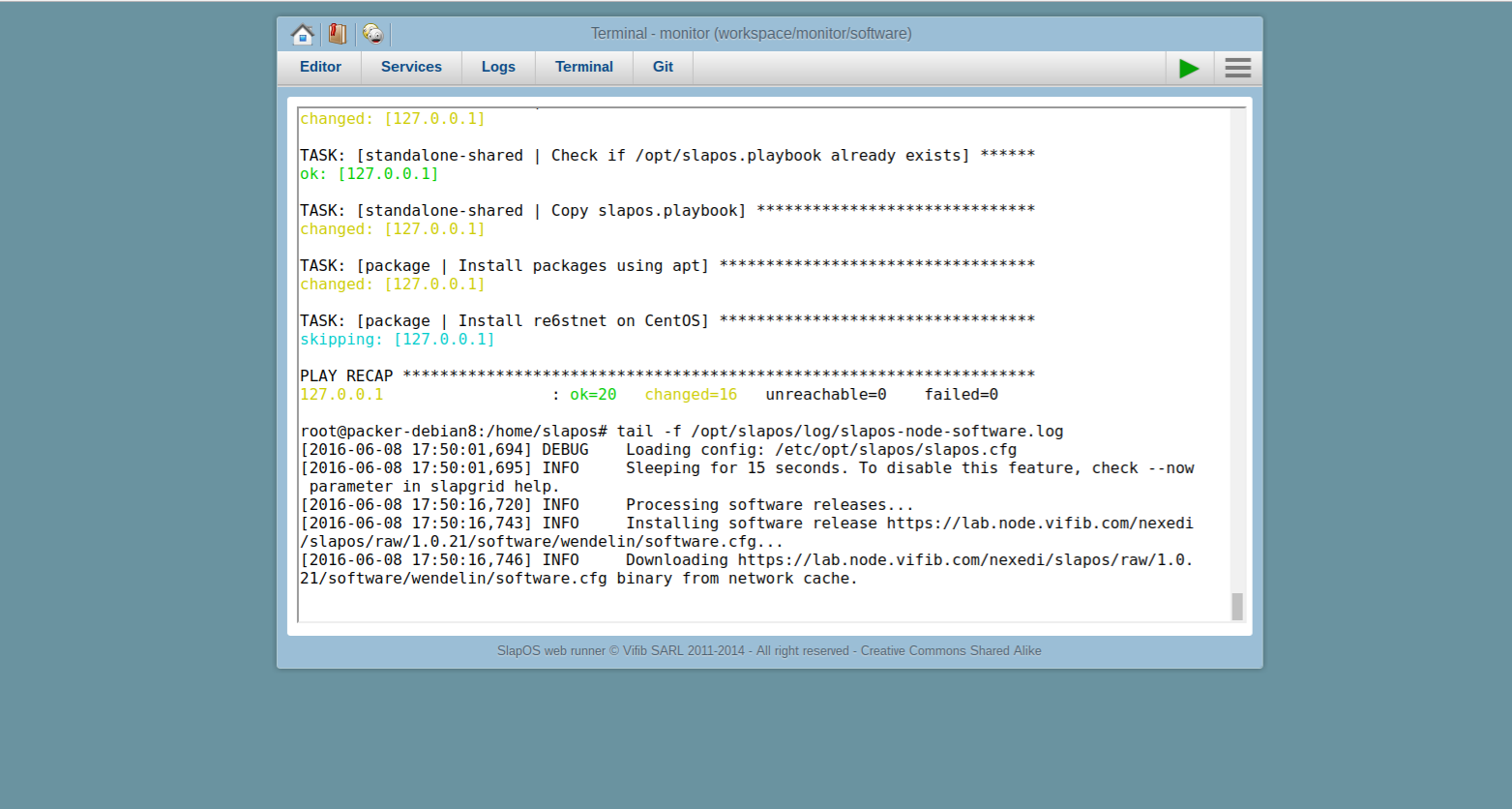
- See SlapOS software installation log:
tail -f /opt/slapos/log/slapos-node-software.log
Todo: Check Software Installaton Status
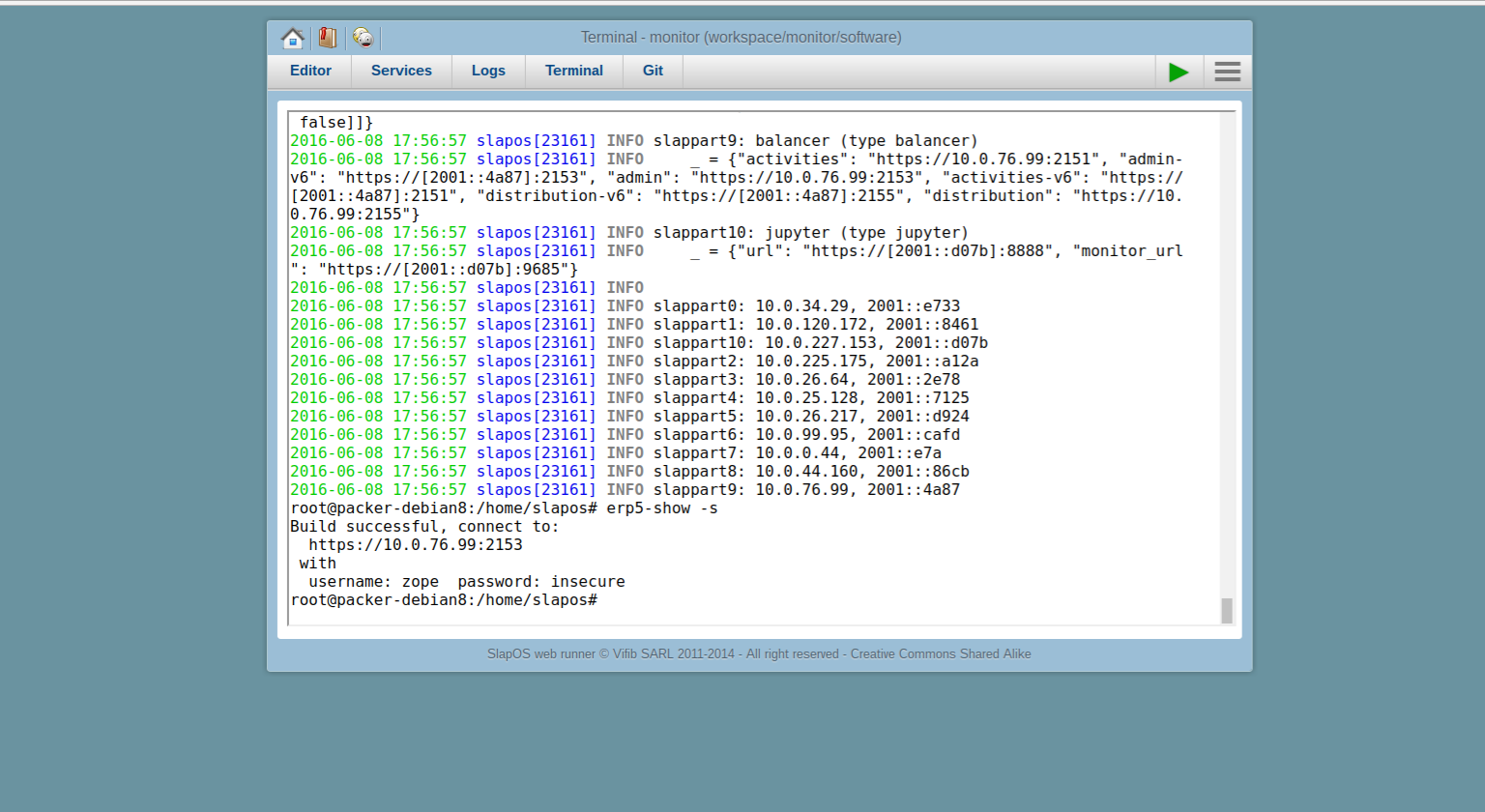
- Check status of Wendelin/ERP5 installation
watch -n 30 erp5-show -s- Once done it will return you an internal IPv4. Note this down
Todo: Socat Bind
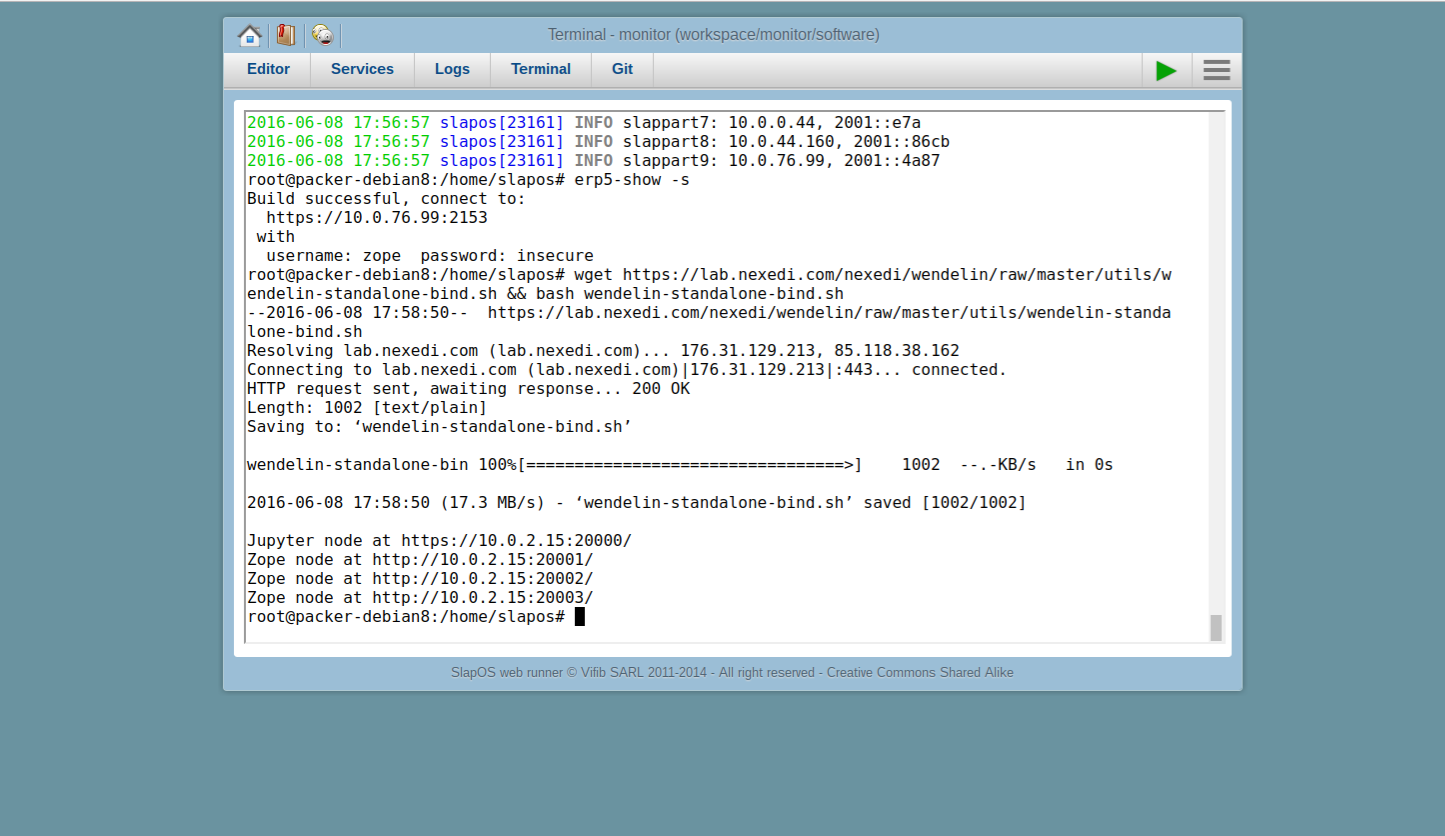
wget https://lab.nexedi.com/nexedi/wendelin/raw/master/utils/wendelin-standalone-bind.sh && bash wendelin-standalone-bind.sh- This will activate urls provided to access Jupyter/ERP5, note them down for later use.
- As mentioned before, socat is used to bind to the correct ports to be able to access Wendelin
- This would normally have to be done by hand inside your SlapOS instance parameters ("nat-rules")
Todo: Test Bindings
- Check if socat works:
ps aux | grep socat
- Check processes:
ps xa | grep runzope
- Check who does what:
grep node-id /srv/slapgrid/slappart*/etc/zope-0.conf
Todo: Configure Wendelin - Login
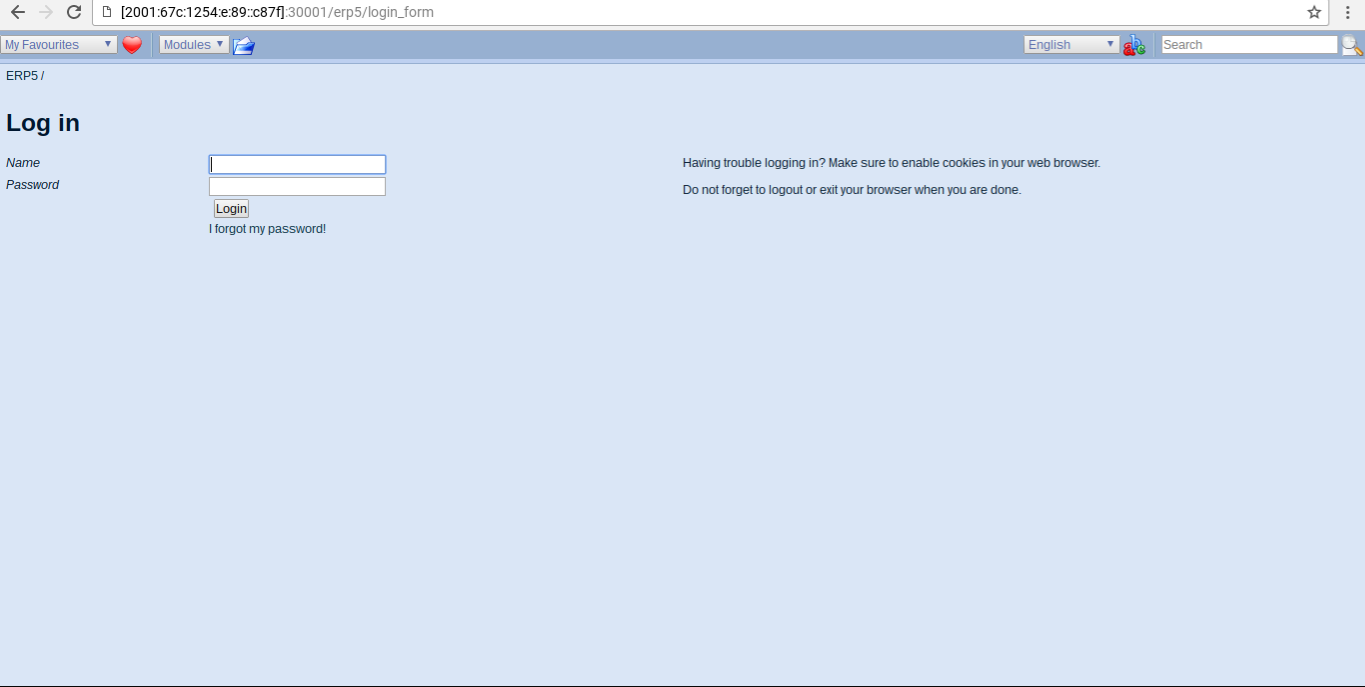
- Go to your Zope 2 Url (
vm[x]30002-url )
- Login using zope/insecure
- My Favorites > Check Site Consistency
Todo: Fix Consistency
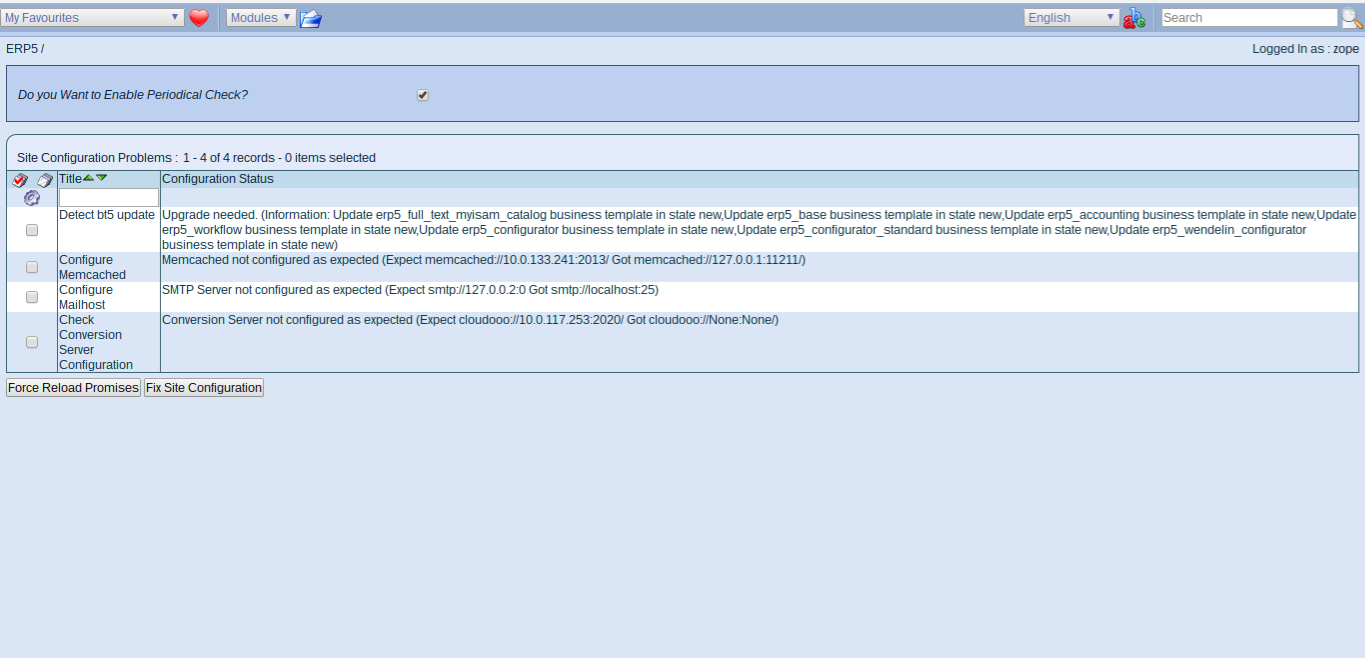
- Select All and Fix Consistencies
- Checking Site Consitency is always the first step when working with a new ERP5 instance
- It ensures all components are up to date and installed correctly
- Next steps are all in Configure Wendelin: Tutorial
Todo: Configure Site
- Once done (!), continue
- Select Configure Site for Wendelin
Todo: Install Configuration
- Select Configuration for Wendelin
- Click "Install" on next screen
- Configuring Site will install a predefined set of business templates
- This could also be done manually, but Wendelin has a predefined configuration, so it can be used directly
Todo: Wait
- Installation may take a few minutes
- Once down, click "Start using your ERP5 System"
- Login again with zope/insecure
Todo: HOTFIX: Add Business Template
- Goto My Favorites > Manage Business Templates
- HOTFIX are addable in live system via business templates
- Business Templates are standard way of adding functionality in ERP5/Wendelin
- Business Templates (bt5) are complete apps or working parts of an application.
- Full list: ERP5 applications
- Allows to recreate the same configuration across multiple instances
- Allows to add hotfixes and patches in case necessary without restarting system
- Detailed instructions in how to install business templates
Todo: Download Business Template
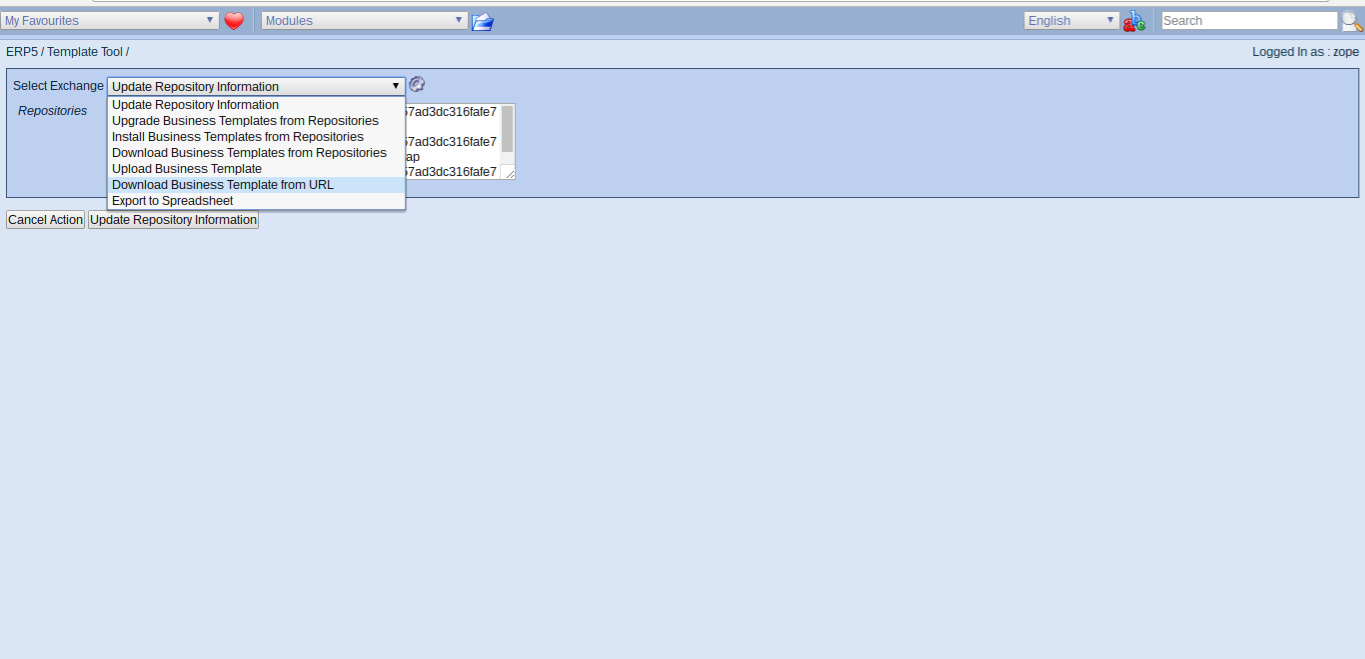
- Click the Export Symbol (red/blue arrows)
- Select Download Business Template from URL
Todo: Enter Business Template URL
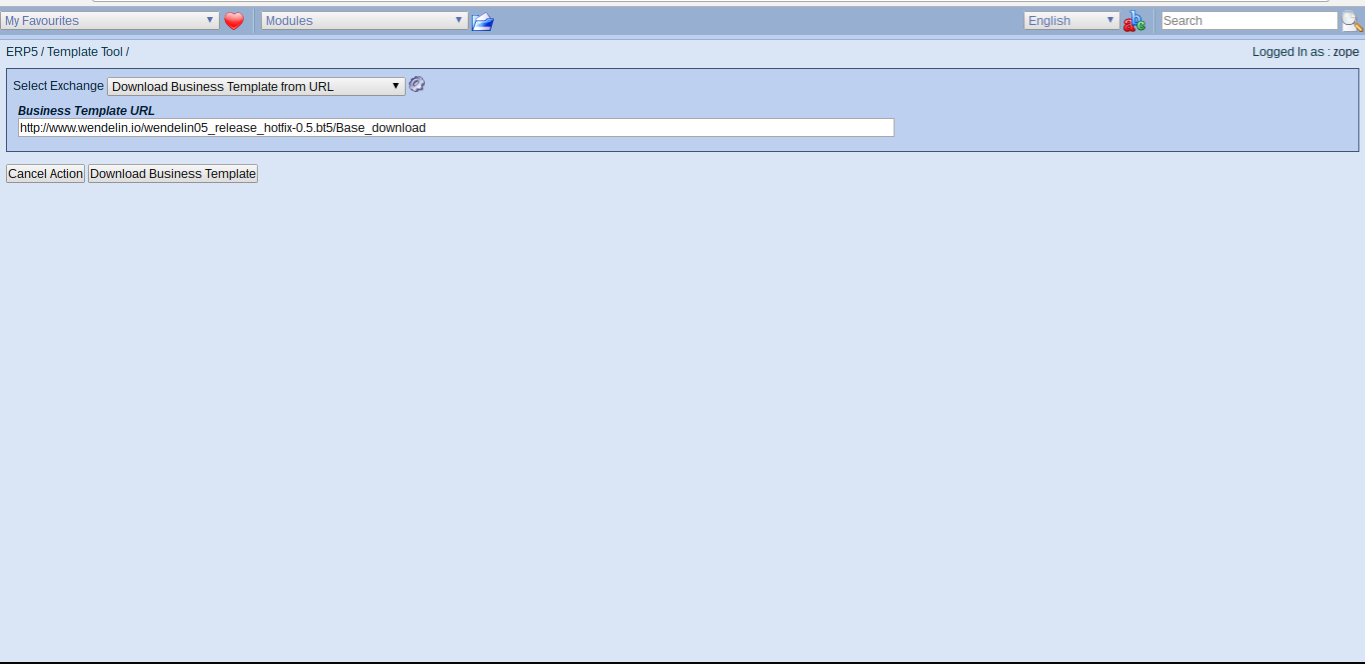
- Enter the HOTFIX Url provided and click to download
http://www.wendelin.io/wendelin05_release_hotfix-0.5.bt5/Base_download- Click download
Todo: Install Business Template
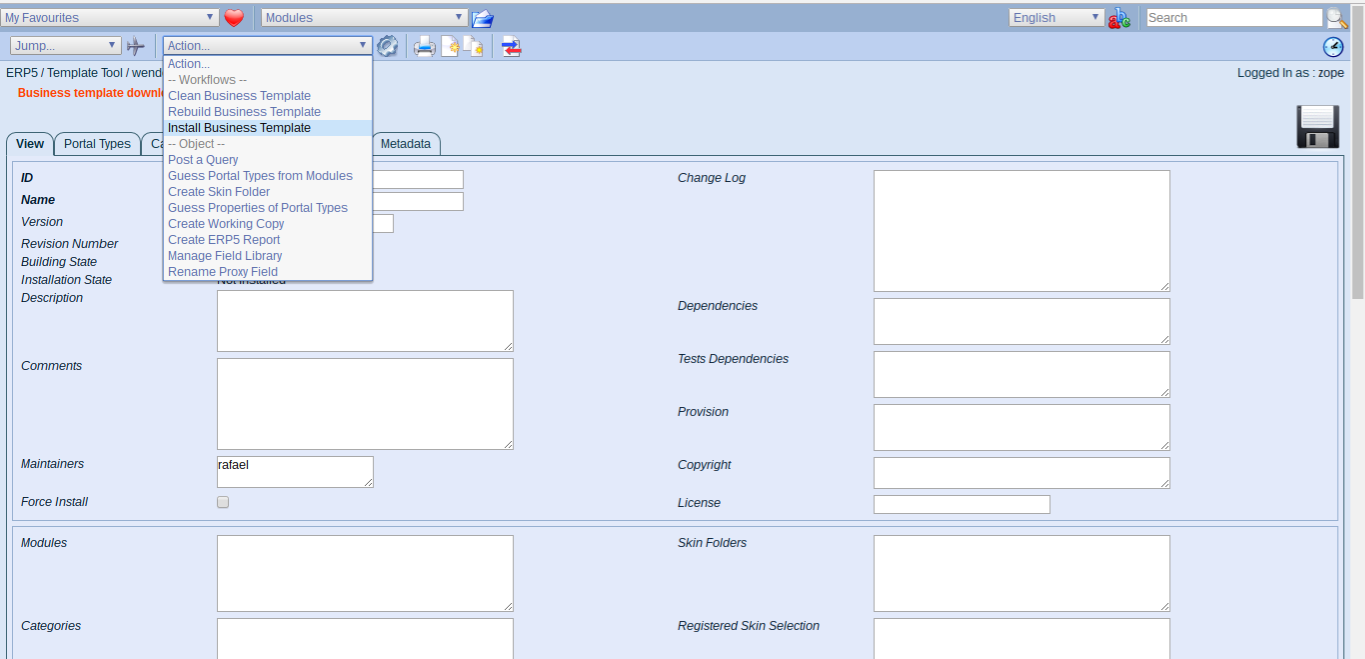
- Once download finishes, go to the business template page
- From actions, select Install Business Template
Todo: Confirm HOTFIX additions
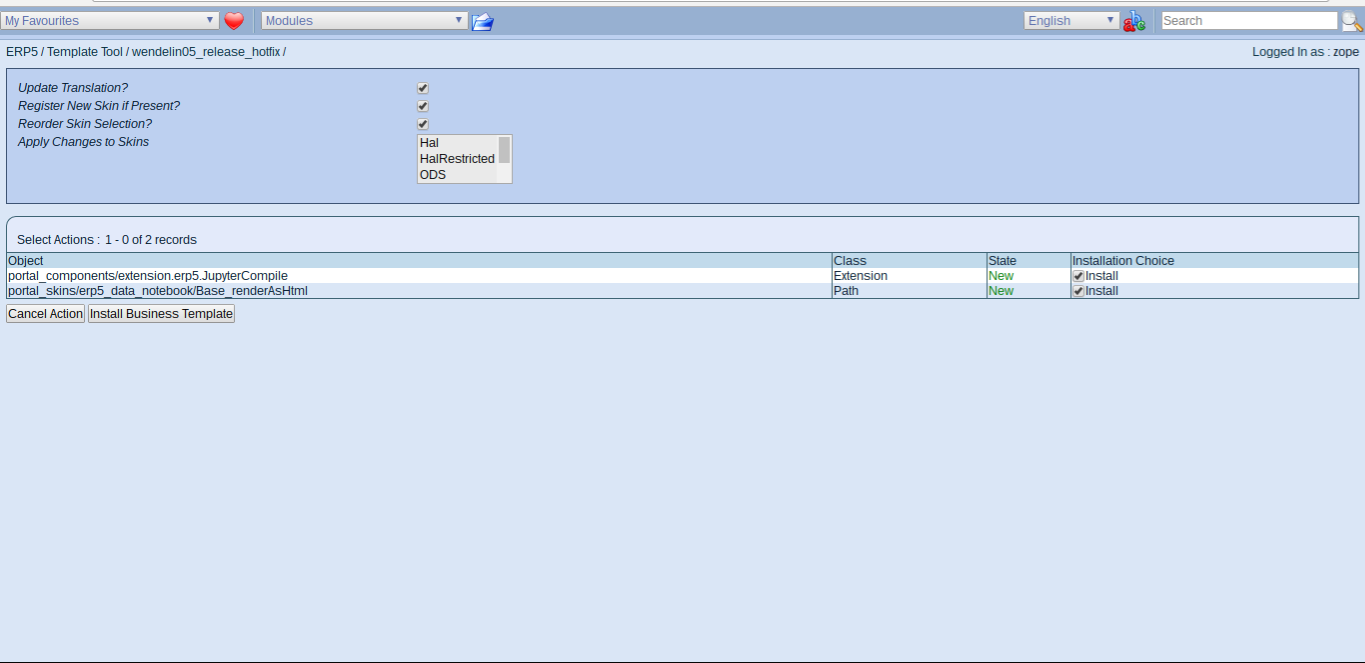
- The dialog will show a list of objects to be added with the installation
- Confirm and install
Todo: Main Interface
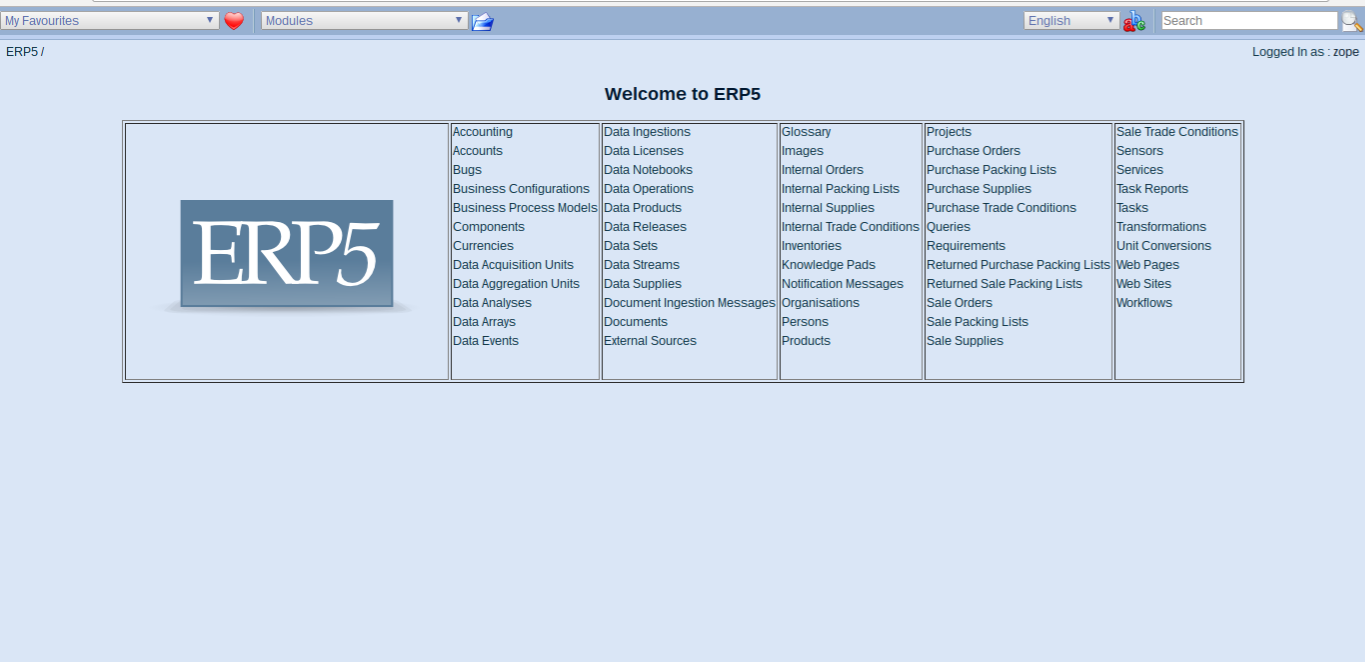
- Go back to the main interface
- Your instance is now ready to use
- The start screen shows a list of modules (data-types) directly accessible
- Modules can be contain anything from Persons, Organizations to Data Streams
- Modules prefixed with Portal are not displayed (e.g. portal ingestion policies)
Todo: Create Ingestion Policy
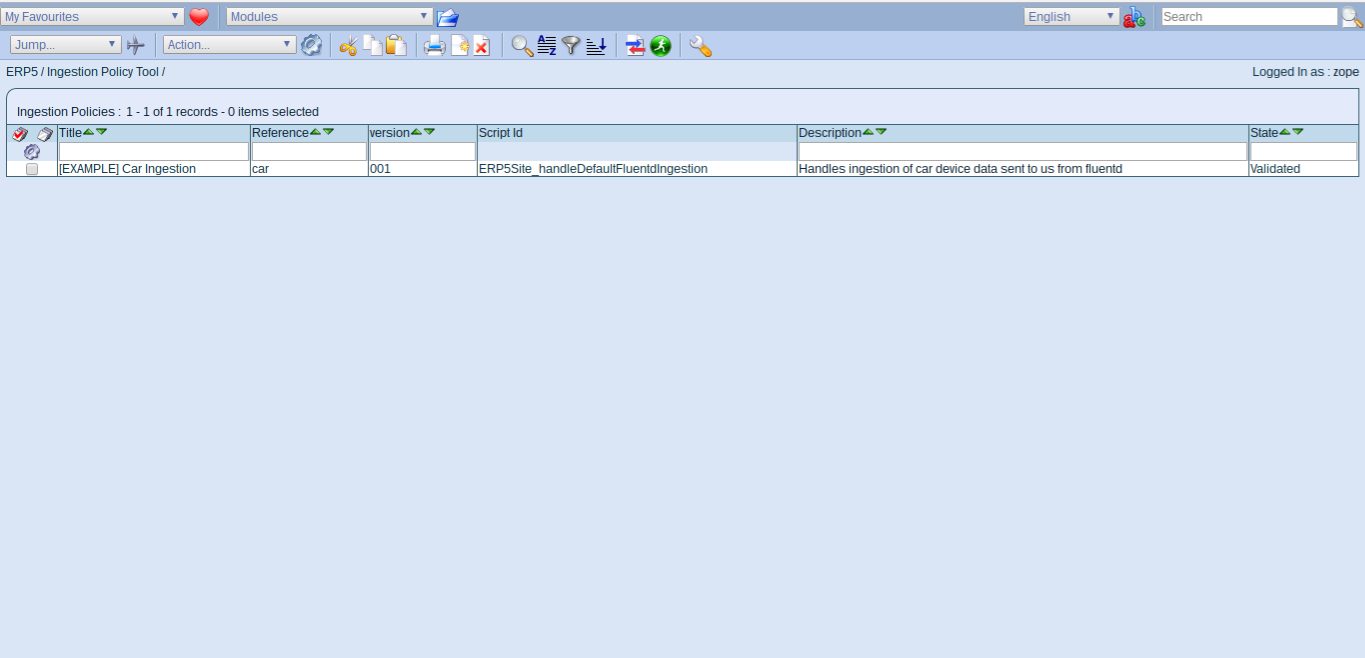
- We now setup Wendelin to receive data from fluentd
- Goto:
http://softinstxxxx.host.vifib.net/erp5/portal_ingestion_policies/
- Security Setting to prevent arbitrary stream from being sent
- Currently fluentd and Wendelin are setup to receive streams of data
- A stream is an existing file to which data is continually appended
- The congestion policy "initializes" a Data Stream (creates a new file)
Todo: Fast Input
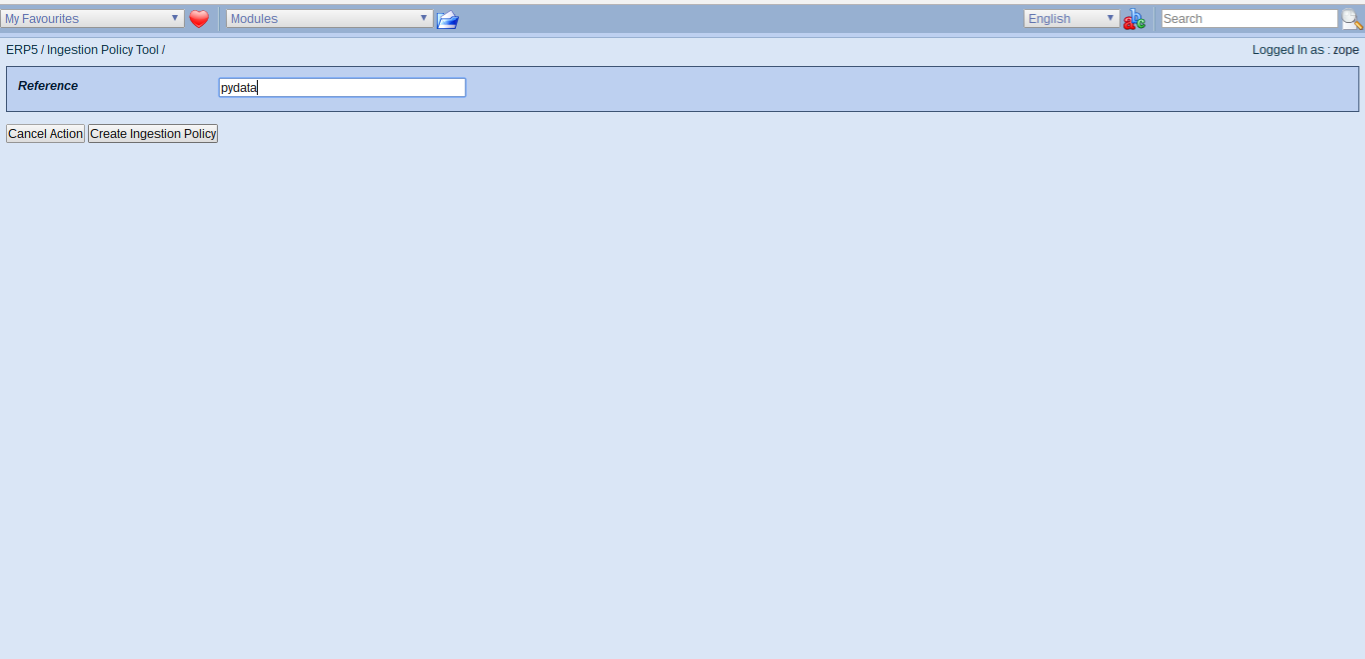
- Hit the "Green Runner" for fast input
- Enter "pydata" as our reference name and save
- This creates a new ingestion policy and corresponding data stream
- The ingestion policy includes default scripts to be called on incoming data
- To modify data handling, you could now define your own script
Todo: Check Data Streams
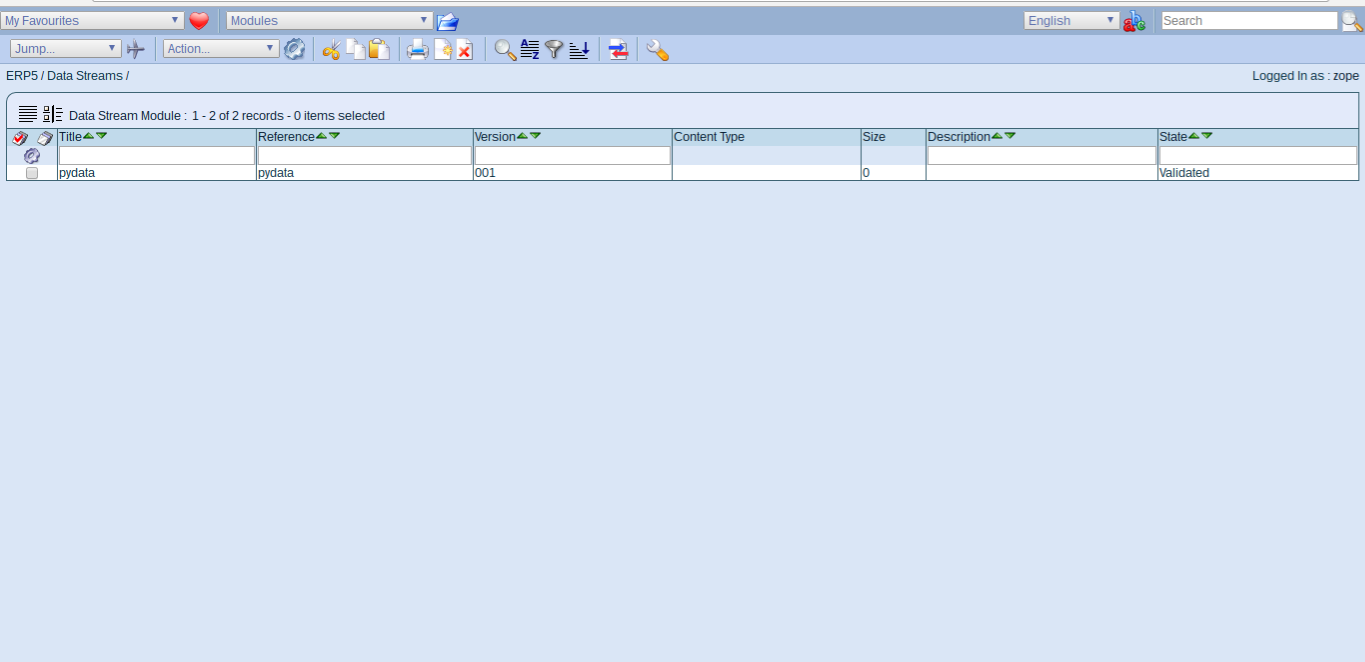
- Switch to Data Stream Module
- You will now have an empty stream, setup to ingest data from fluentd
- Click on the stream. You can also upload data by hand if you like to experiment
Audio: Simulate IOT Sensor
Wendelin in Production

- First Wendelin prototype in production to monitor wind turbines.
- Wendelin used to collect data and manage wind parks.
- Machine Learning for failure prediction, structural health monitoring.
Wendelin in Production

- Turbine equipped with multiple sensors per blade, PC collecting sensor data
- PC includes fluentd for ingesting into Wendelin (network availability!)
- Tutorial: we use same setup, sensor - Fluentd - Wendelin
Basic FluentD

- FluentD is open source unified data collector
- Has a source and destination, generic, easy to extend
- Can handle data collection even under poor network conditions
Complex FluentD

- Setup of FluentD can be much more complex
- In Wendelin production, every turbine has its own FluentD
- Tutorial simulates the same, all VM have their own FluentD
Todo: Record Audio
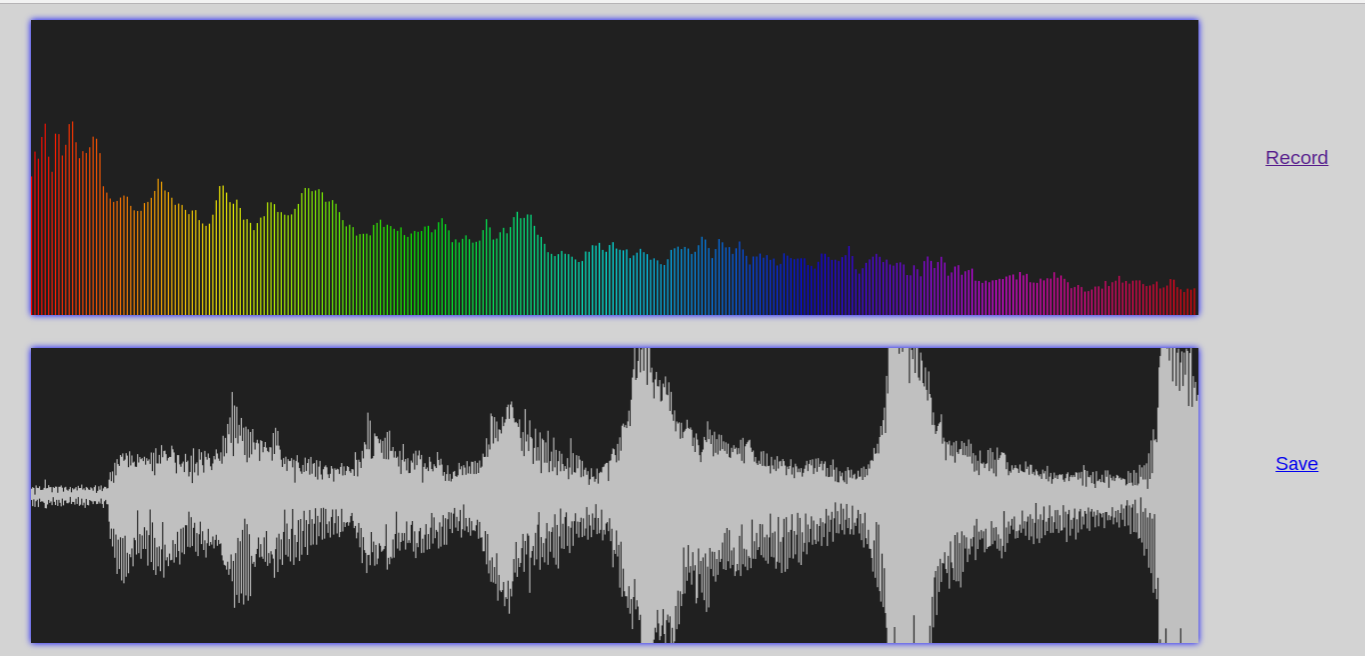
Todo: Access Monitor using fluentD
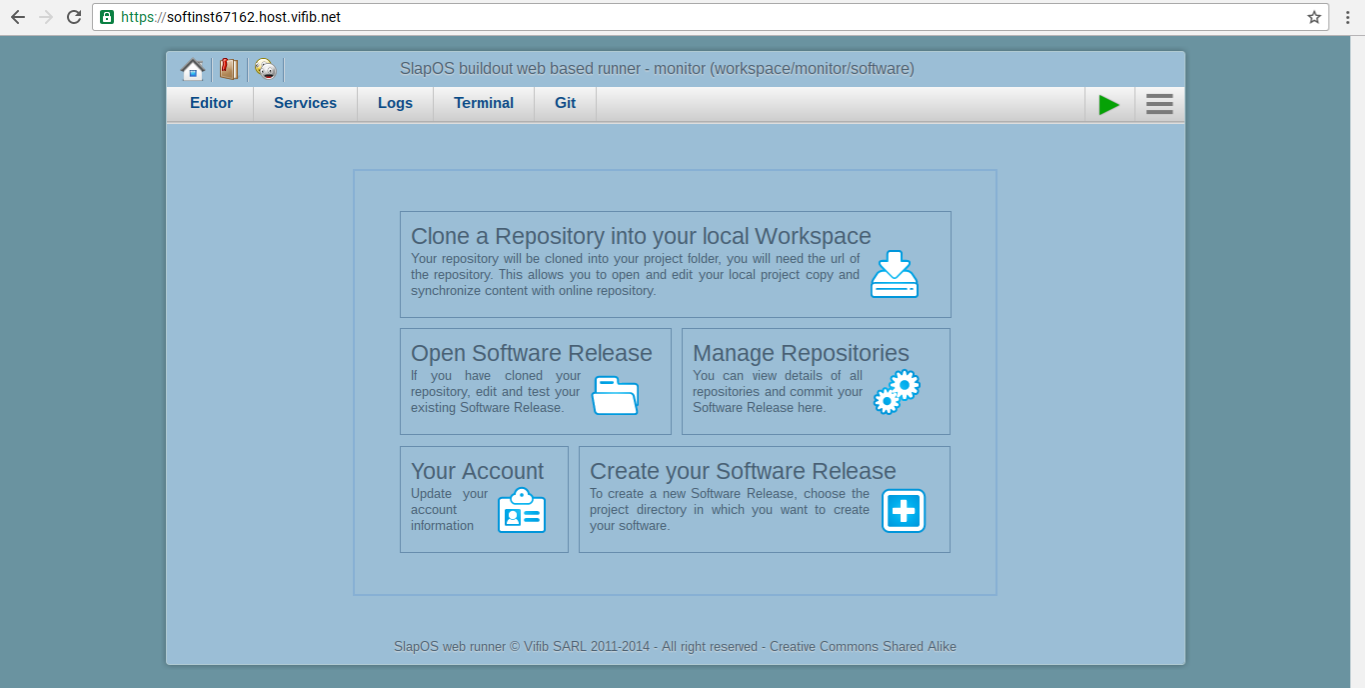
- Access Monitor at:
https://softinst67162.host.vifib.net/
- Go to the Editor, click "This Project"
Todo: Upload to Monitor
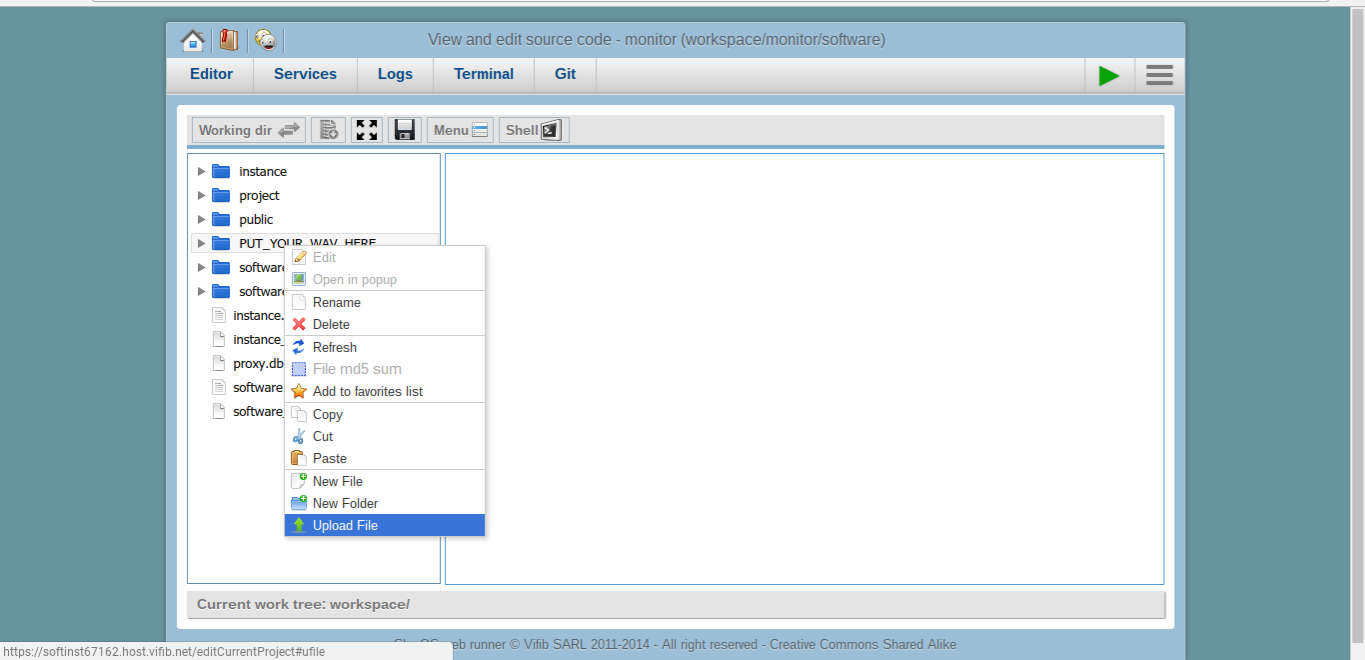
- We already made a folder for uploads for this tutorial
- Left click and select upload file
Todo: Forward File to fluentD
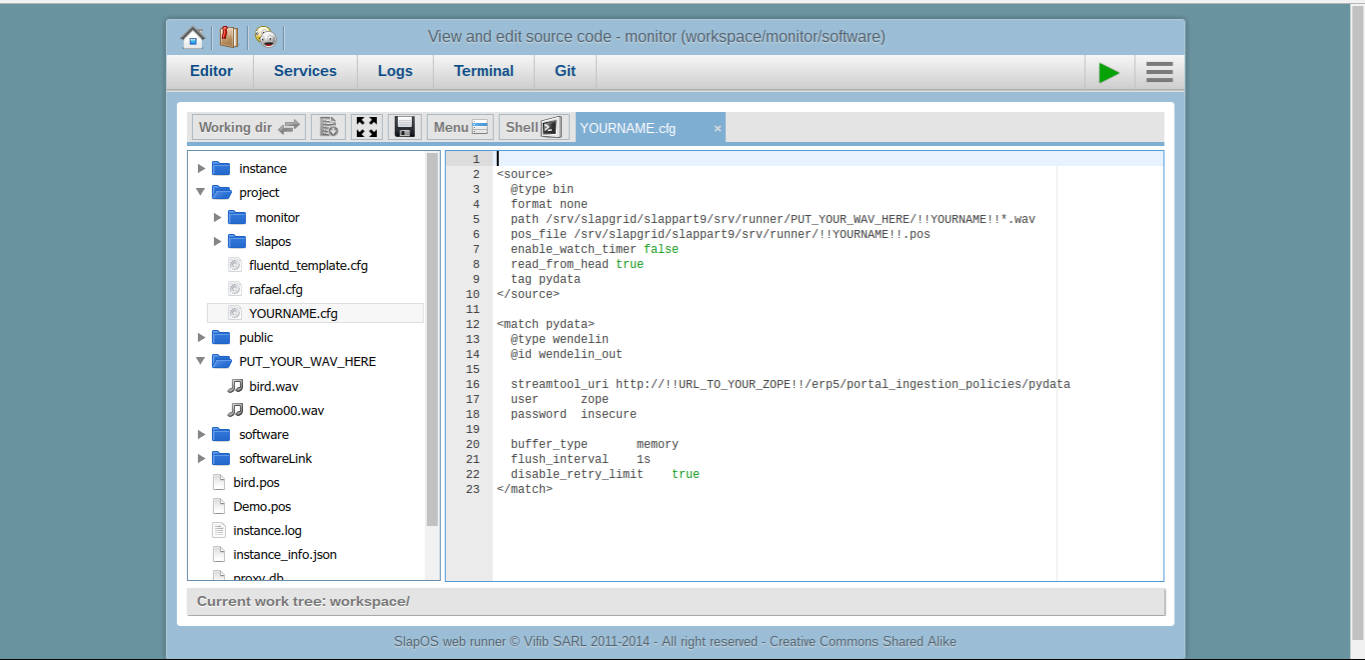
- In the Editor, open folders project > slapos
- Create a new file, give it your name
- Code on next slide (please copy&paste)
- We are now creating a configuration file to pass to fluentd
- The file contains all parameters for fluentD regarding data source and destination
- Normally this is set upfront, but for the tutorial we hardcode
Todo: FluentD Configuration File (Gist)
<source>
@type bin
format none
path
/srv/slapgrid/slappart9/srv/runner/PUT_YOUR_WAV_HERE/!!YOURNAME!!*.wav
pos_file /srv/slapgrid/slappart9/srv/runner/!!YOURNAMEGOESHERE!!.pos
enable_watch_timer false
read_from_head true
tag pydata
</source>
<match pydata>
@type wendelin
@id wendelin_out
streamtool_uri
http://!!URL_TO_YOUR_ZOPE!!/erp5/portal_ingestion_policies/pydata
user zope
password insecure
buffer_type memory
flush_interval 1s
disable_retry_limit true
</match>
- Note that tag will be the name of your data-ingestion-policy/stream
Todo: Save and send from Terminal
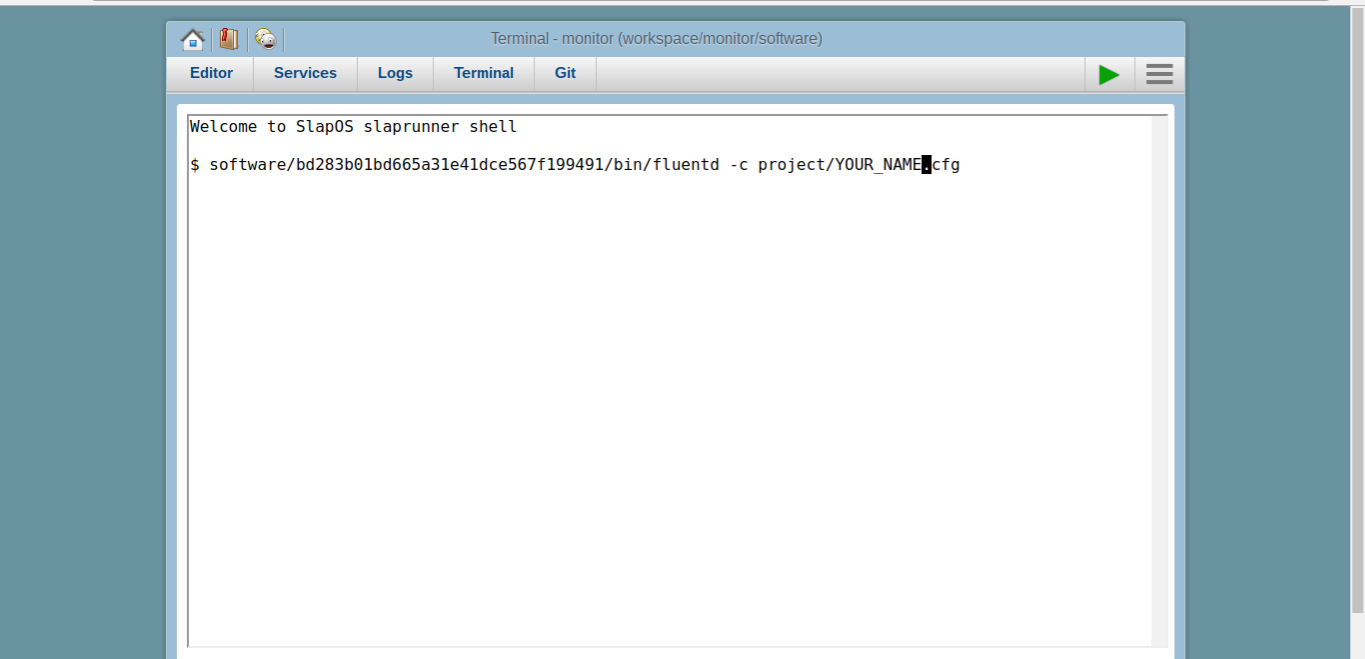
- Switch to the terminal and enter:
software/bd283b01bd665a31e41dce567f199491/bin/fluentd -c project/YOUR_NAME.cfg- To pass your configuration including what file to send to Wendelin
Todo: Save and send from Terminal
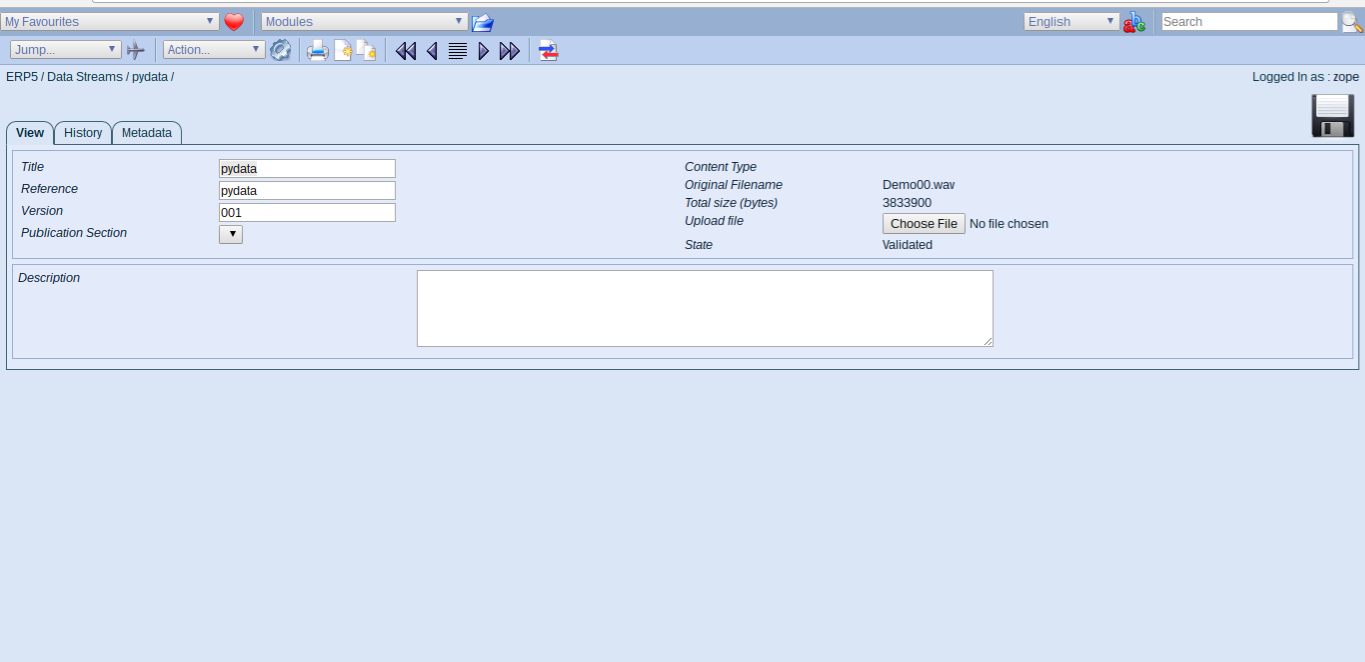
- Head back to Wendelin/ERP5
- In the Data Stream Module, check the file size of the pydata stream
- It should now show a file size larger than 0
Analyse: Work with Ingested Data
Out-of-Core

- Wendelin.Core enables computation beyond limits of existing RAM
- We have integrated Wendelin and Wendelin.Core With Jupyter
- ERP5 Kernel (out-of-core compliant) vs. Python 2 Kernel (default)
Todo: Head to Jupyter (Notebook)
- Head to Juypter
http://[x].pydata-class.erp5.cn
- Start a new ERP5 Notebook
- This will make sure you use the ERP5 Kernel
- The Python 2 Kernel is the default Jupyter Kernel
- Using Python 2 will disregard Wendelin and Wendelin.Core, so it's basic Jupyter
- Using ERP5 Kernel will use Wendelin.core in the background
- To make good use of it, all code written should be Out-of-core "compatible"
- For example you should not just load a large file into memory (see below)
Todo: Learn ERP5 Kernel (Notebook)
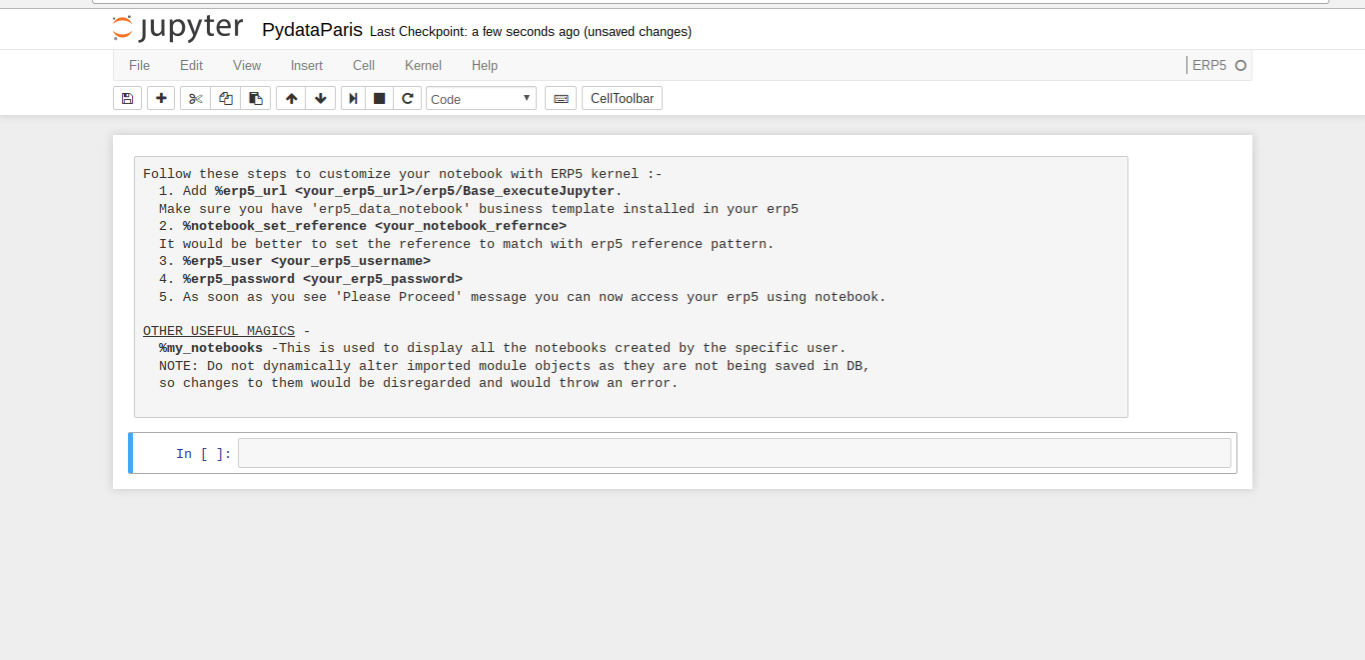
- Note you have to connect to Wendelin/ERP5
- The reference you set will store your notebook in the Date Notebook Module
- Passing login/password will authenticate Juypter with Wendelin/ERP5
- Note that your ERP5_URL in this case should be your internal url
- You can retrieve it be running
erp5-show -s in your webrunner terminal
- Note, outside of the tutorial we would set the external IPv6 adress of ZOPE
Todo: Getting Started (Notebook)
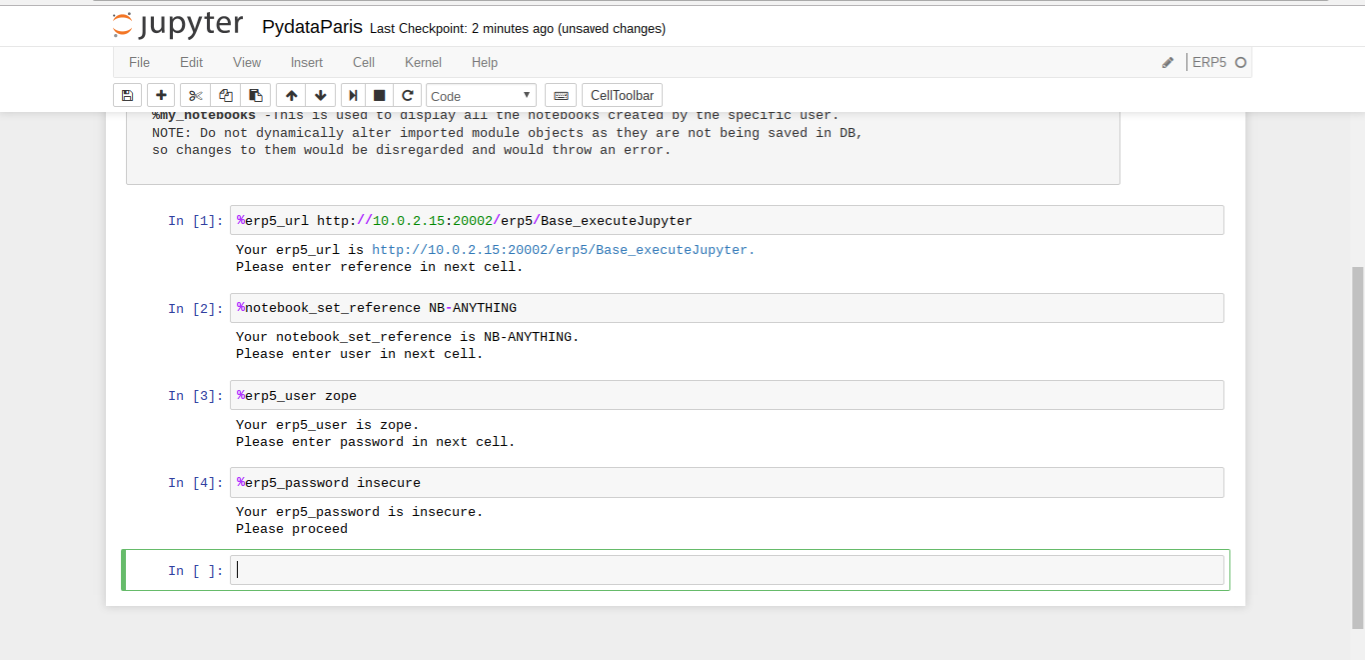
- Connect, set arbitrary reference and authenticate
Todo: Accessing Objects (Notebook)
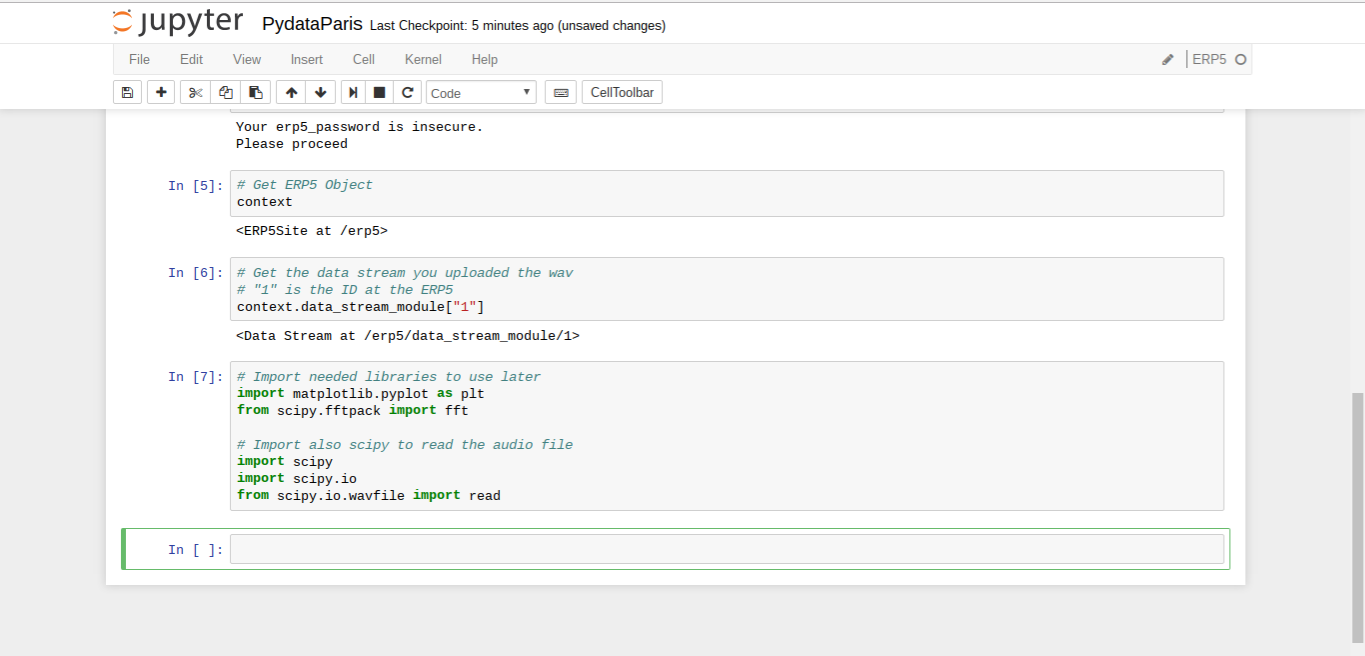
- Import necessary libs
- Type
context , this will give you the Wendelin/ERP5 Object
- Type
context.data_stream_module["1"] to get your uploaded sound file
- Accessing data works the same ways throughout
[IPv6]:30002/erp5/[module_name]/[id]
- All modules you see on the Wendelin/ERP5 start page can be accessed like this
- Once you have an object you can manipulate it
- Note that accessing a file by internal id (1) is only one way
- The standard way would be using the reference of the respective object, which will also allow to user portal_catalog to query
Todo: Accessing Data Itself (Notebook)
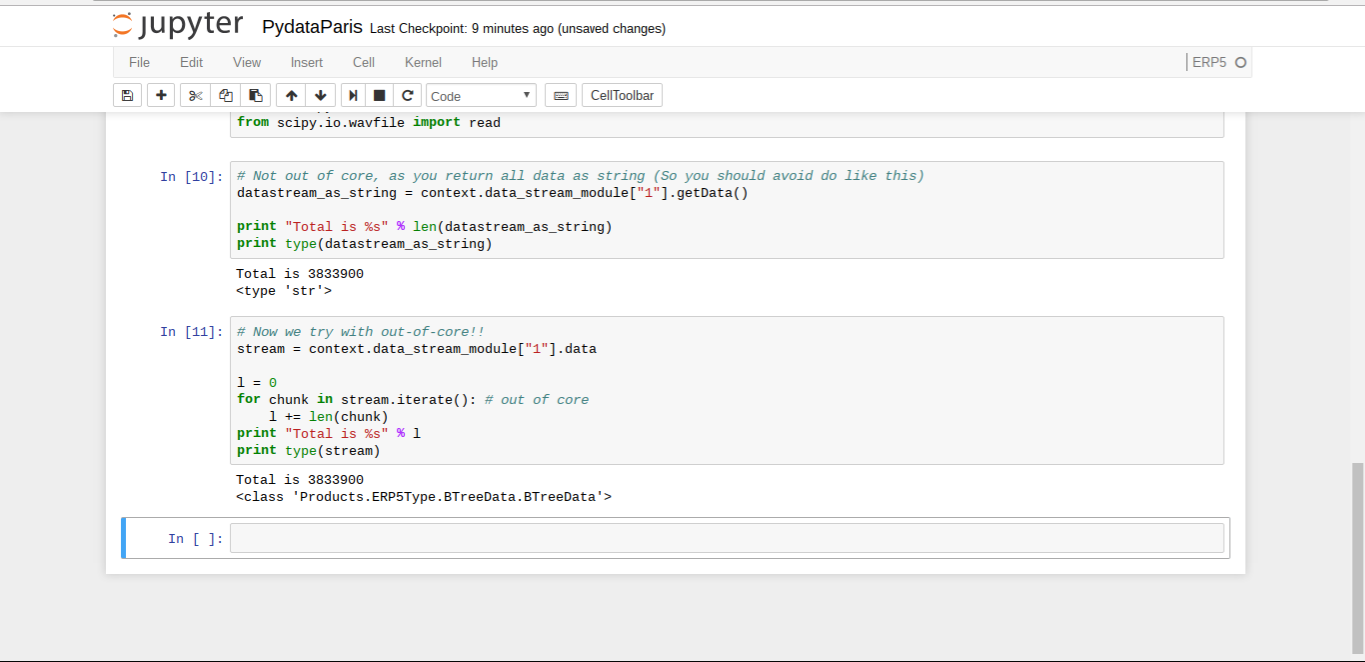
- Try to get the length of the file using
getData and via iterate
- Note then when using ERP5 kernel all manipulations should be "Big Data Aware"
- Just loading a file via getData() works for small files, but will break with volume
- It's important to understand that manipulations outside of Wendelin.Core need to be Big Data "compatible"
- Internally Wendelin.Core will run all manipulations "context-aware"
- An alternative way to work would be to create your scripts inside Wendelin/ERP5 and call them from Juypter
- Scripts/Manipulations are stored in Data Operations Module
Todo: Compute Fourier (Notebook)
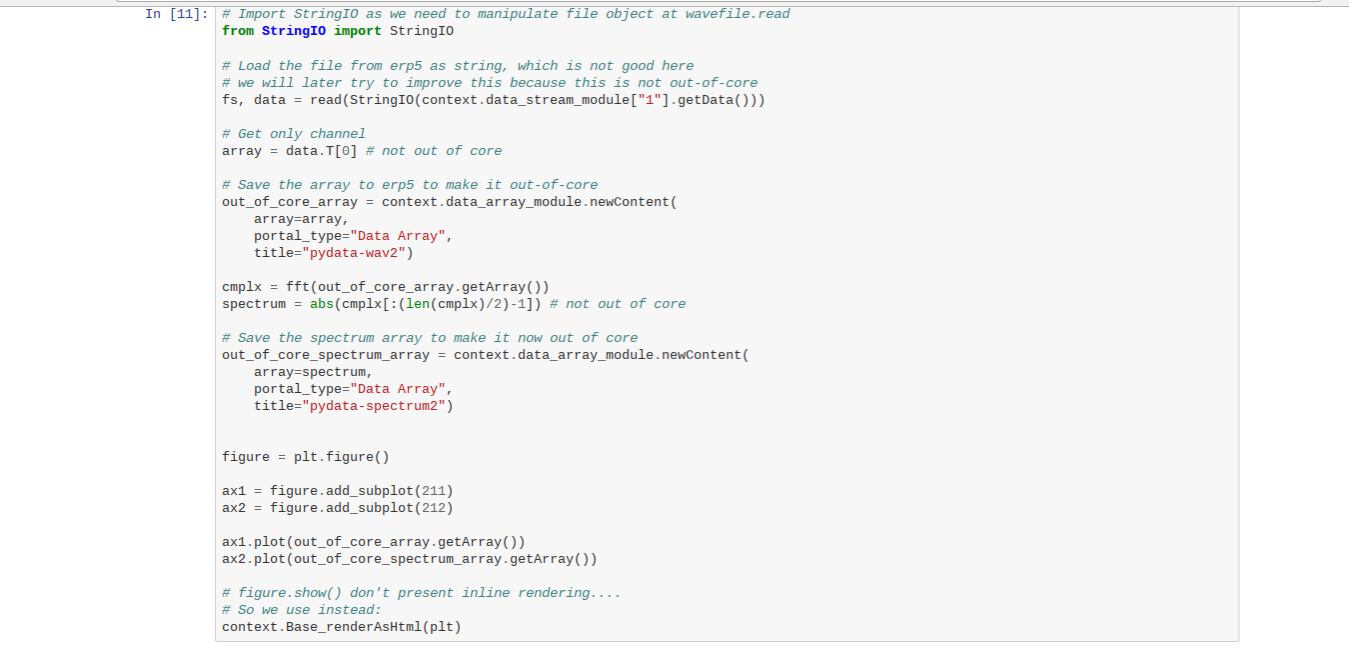
- Proceed to fetch data using
getData for now
- Extract one channel, save it back to Wendelin and compute FFT
- Note, that ERP5 kernel at this time doesn't support
%matplotlib inline
- Note the way to call methods from Wendelin/ERP5 (
Base_renderAsHtml )
- Wendelin/ERP5 has a system of method acquistion. Every module can come with its own module specific methods and method names are always context specific (
[object_name]_[method_name] ). Base methods on the other hand are core methods of Wendelin/ERP5 and applicable to more than one object.
Todo: Display Fourier (Notebook)
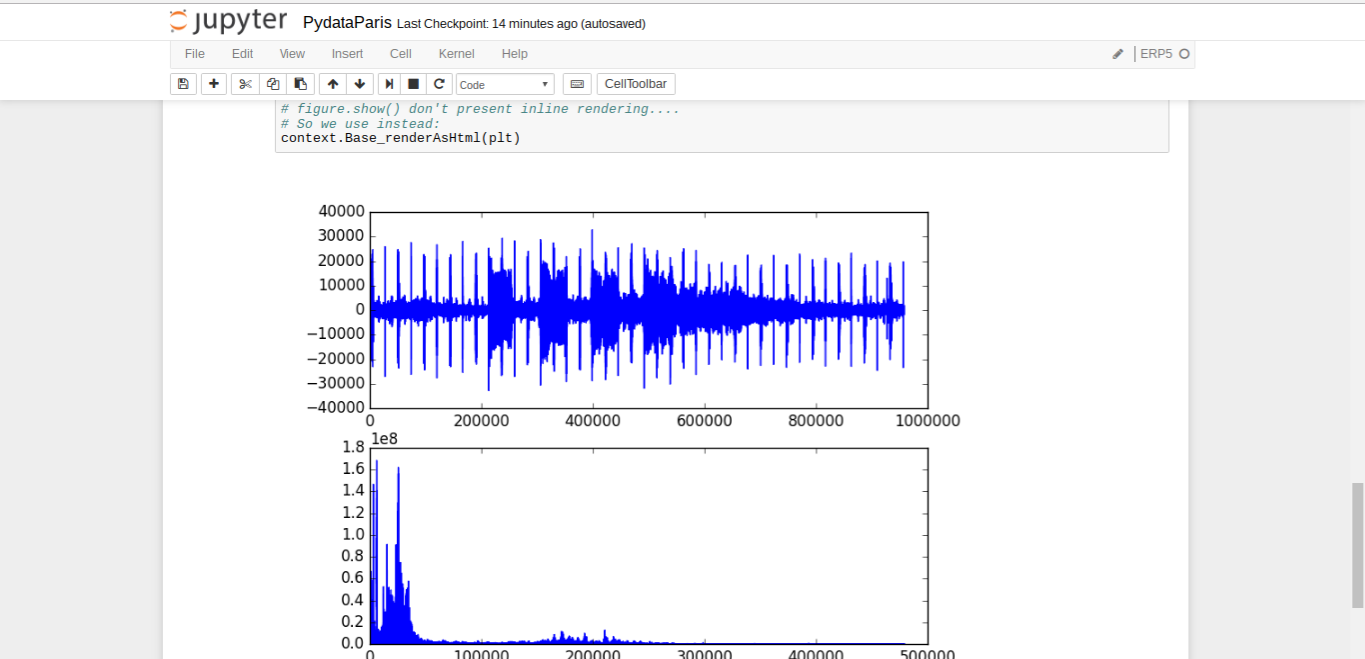
- Check the rendered Fourier graphs of your recorded sound file
Todo: Save Image (Notebook)
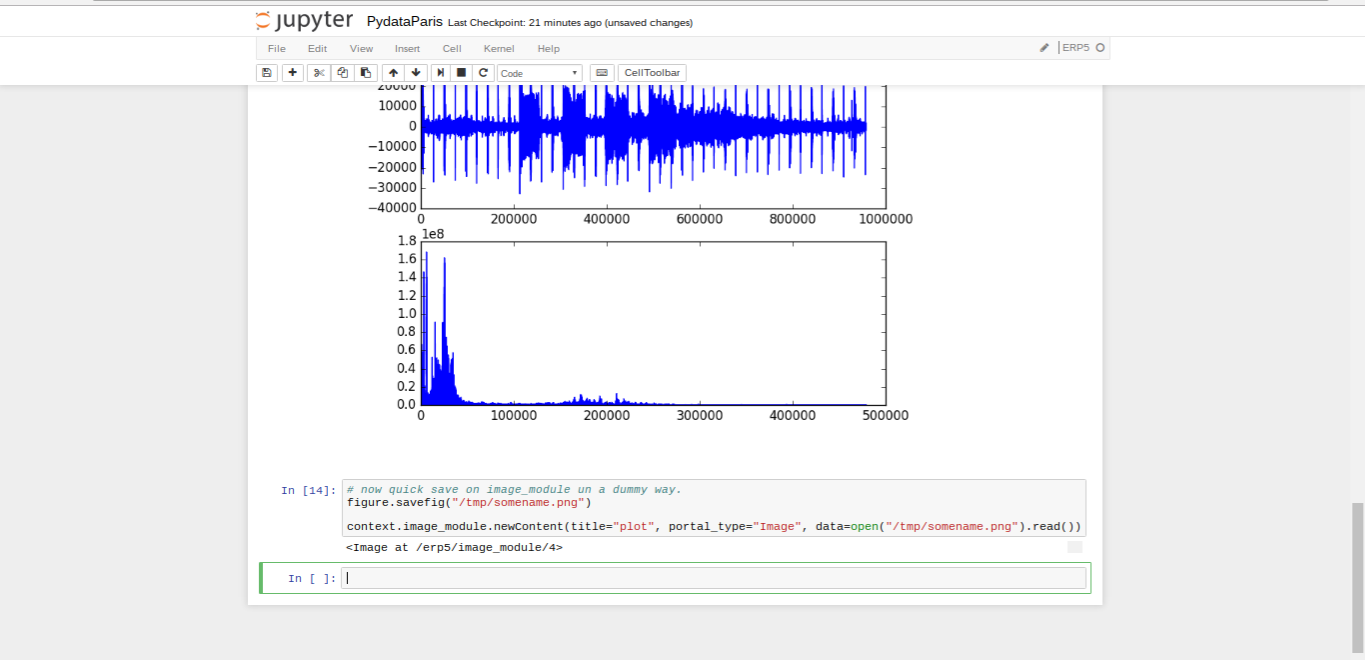
- Save the image back to Wendelin/ERP5.
Todo: Create BigFile Reader (Notebook)
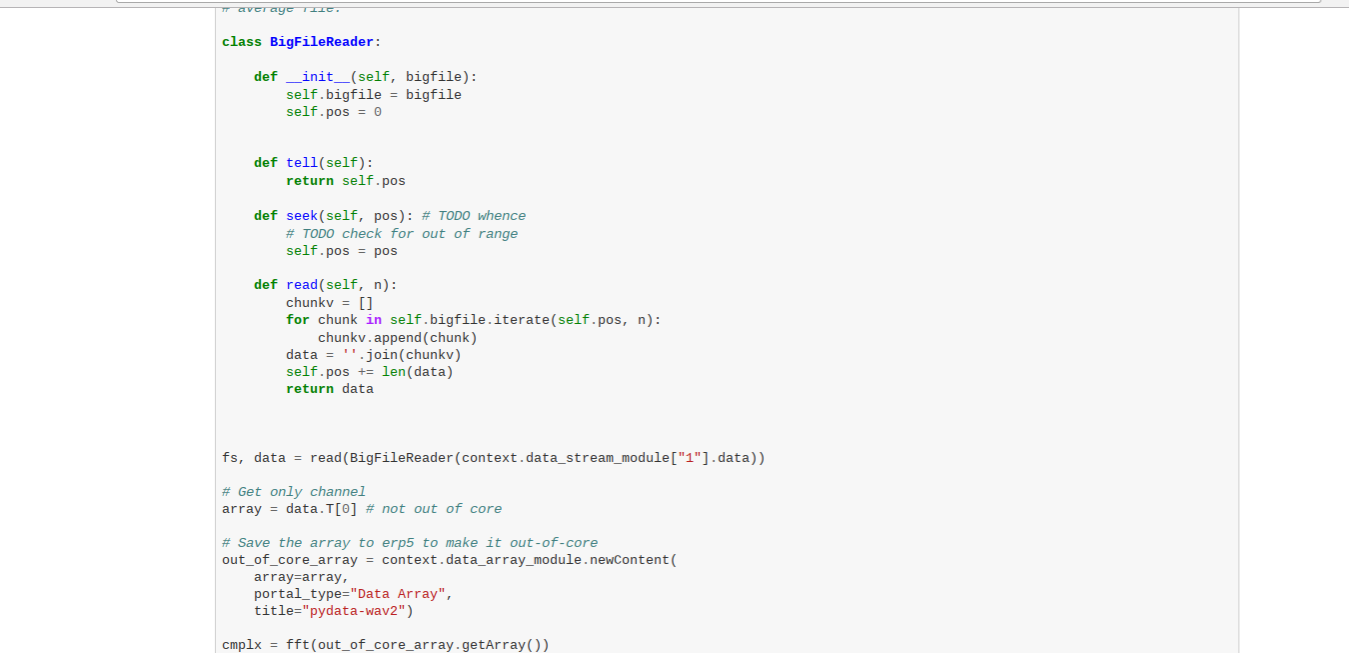
- Add a new class BigFileReader
- Allows to pass out-of-core objects
Todo: Rerun using Big File Reader (Notebook)
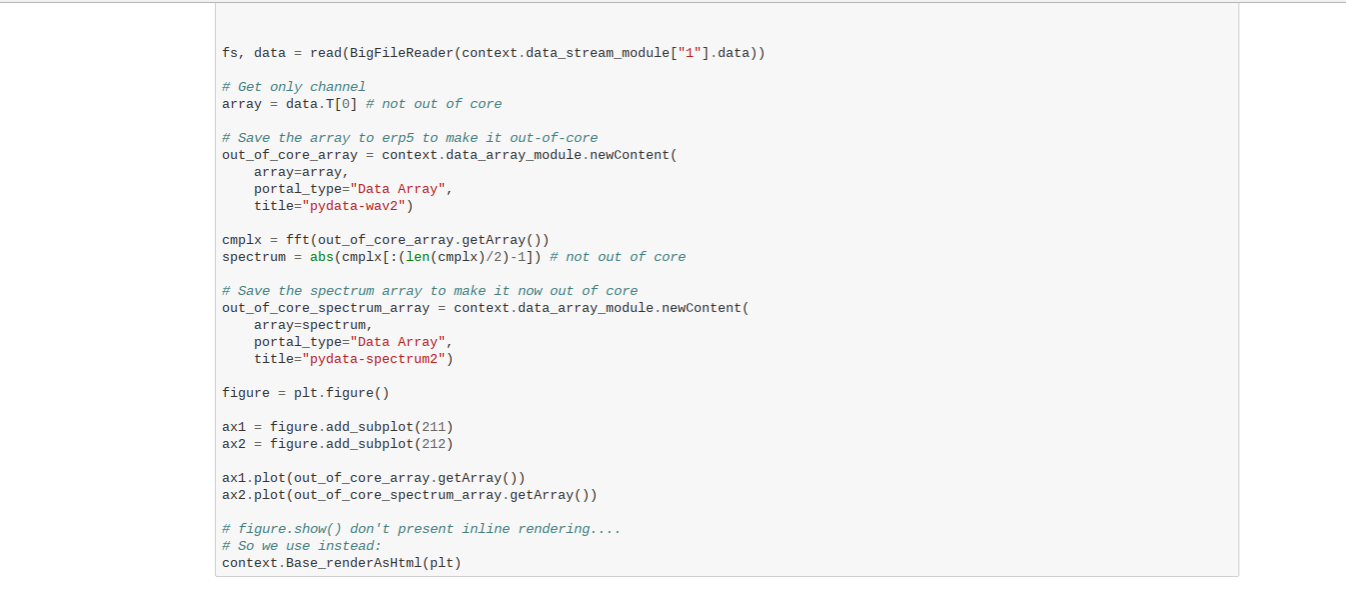
- Rerun using the Big File Reader
- Now one more step is out of core compliant
- Verify graphs render the same
- We are now showing how to step by step convert our code to being Out-of-Core compatible
- This will only be possible for code we write ourselves
- Whenever we have to rely on 3rd party libraries, there is no guarantee that data will be handled in the correct way. The only option to be truly Out-of-Core is to either make sure the 3rd party methods used are compatible and fixing them accordingly/committing back or to reimplement a 3rd party library completely.
Todo: Redraw from Wendelin (Notebook)
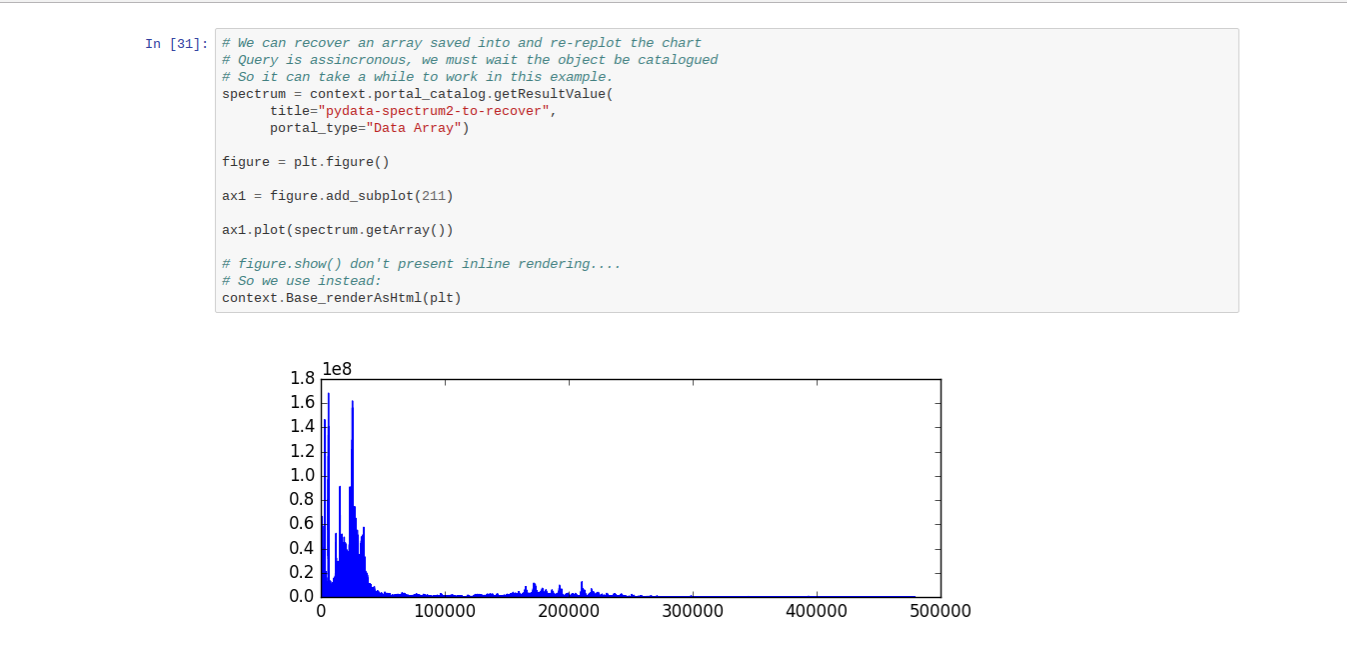
- Redraw the plot directly from data stored in Wendelin/ERP5
Todo: Verify Images are Stored
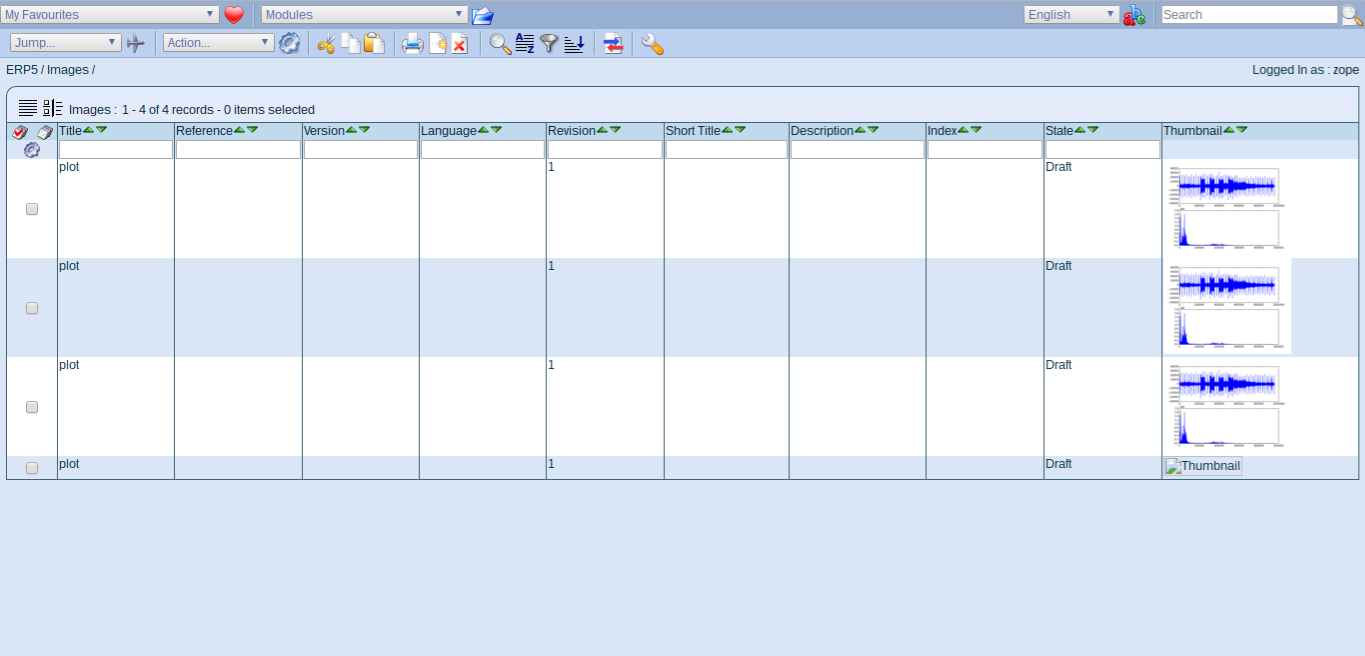
- Head back to Wendelin/ERP5
- Go to Image module and verify your stored images are there.
Todo: Verify Data Arrays are Stored
- Switch to the Data Array module
- Verify all computed files are there.
Visualize: Display computed data
Running Web Sites from Wendelin
- Last step is to display results in a web app
- Head back to main section in Wendelin/ERP5
- Go to Website Module
WebSite Module
- Website Module contains websites
- Open renderjs_runner - ERP5 gadget interface
- Front end components are written with two frameworks, jIO and renderJS
- jIO (Gitlab) is used to access documents across different storages
- Storages include: Wendelin, ERP5, Dropbox, webDav, AWS, ...
- jIO includes querying, offline support, synchronization
- renderJS (Gitlab) allows to build apps from reusable components
- Both jIO/renderJS are asynchronous using promises
Renderjs Runner
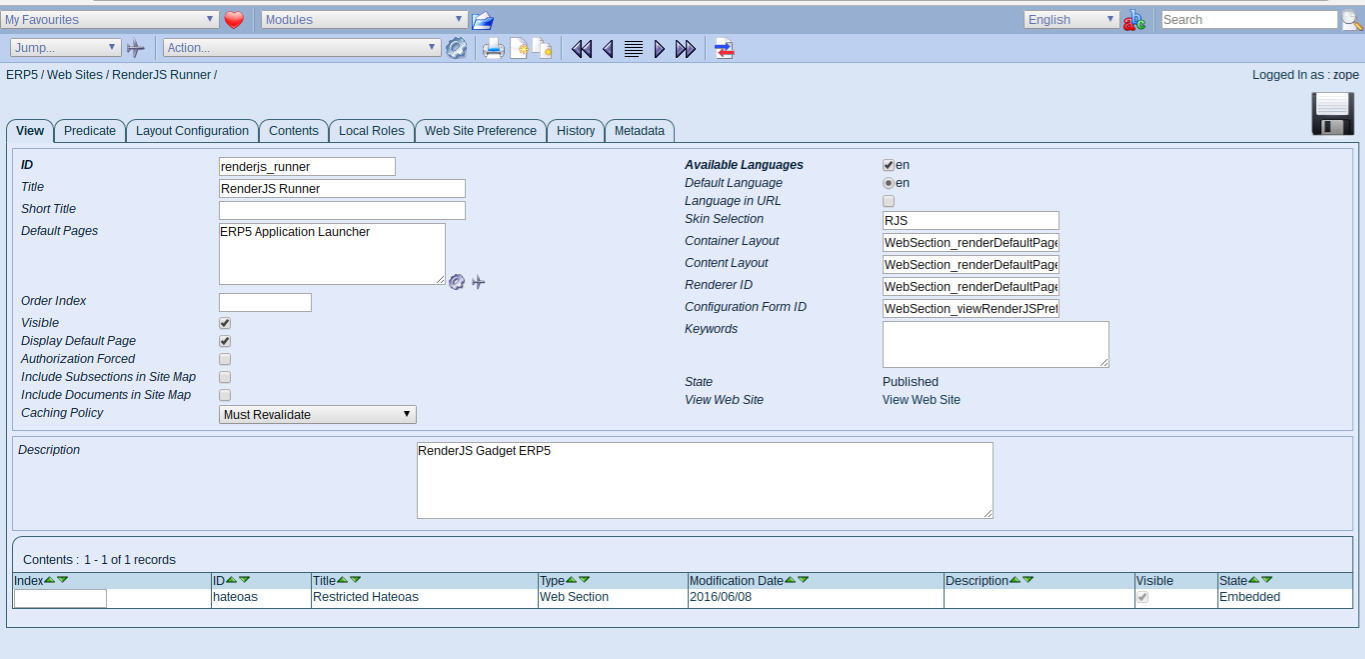
- Parameters for website module
- see ERP5 Application Launcher - base gadget
- Open new tab:
http://softinstxxxx/erp5/web_site_module/renderjs_runner/
- Apps from gadgets are built as a tree structure, the application launcher is the top gadget
- All other gadgets are child gadgets of this one
- RenderJS allows to publish/aquire methods from other gadget to keep functionality encapsulated
Renderjs Web App
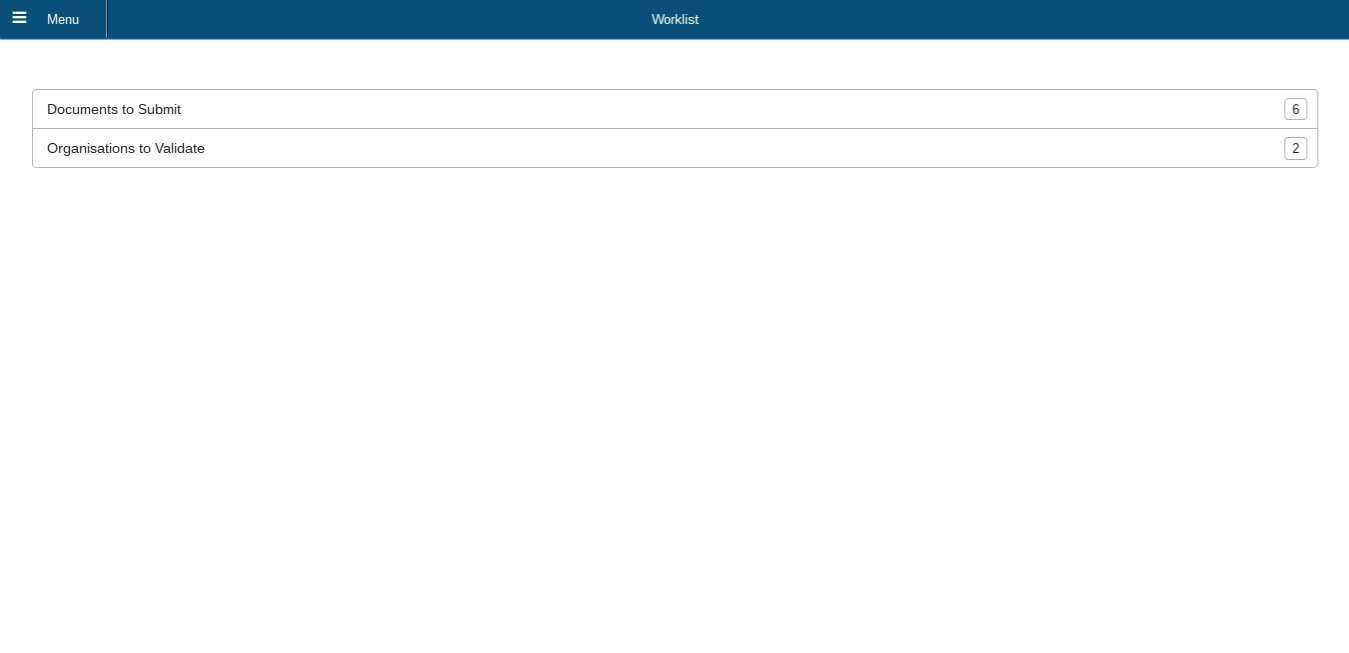
- ERP5 interface as responsive application
- We will now create an application like this to display our data
Todo: Clone Website
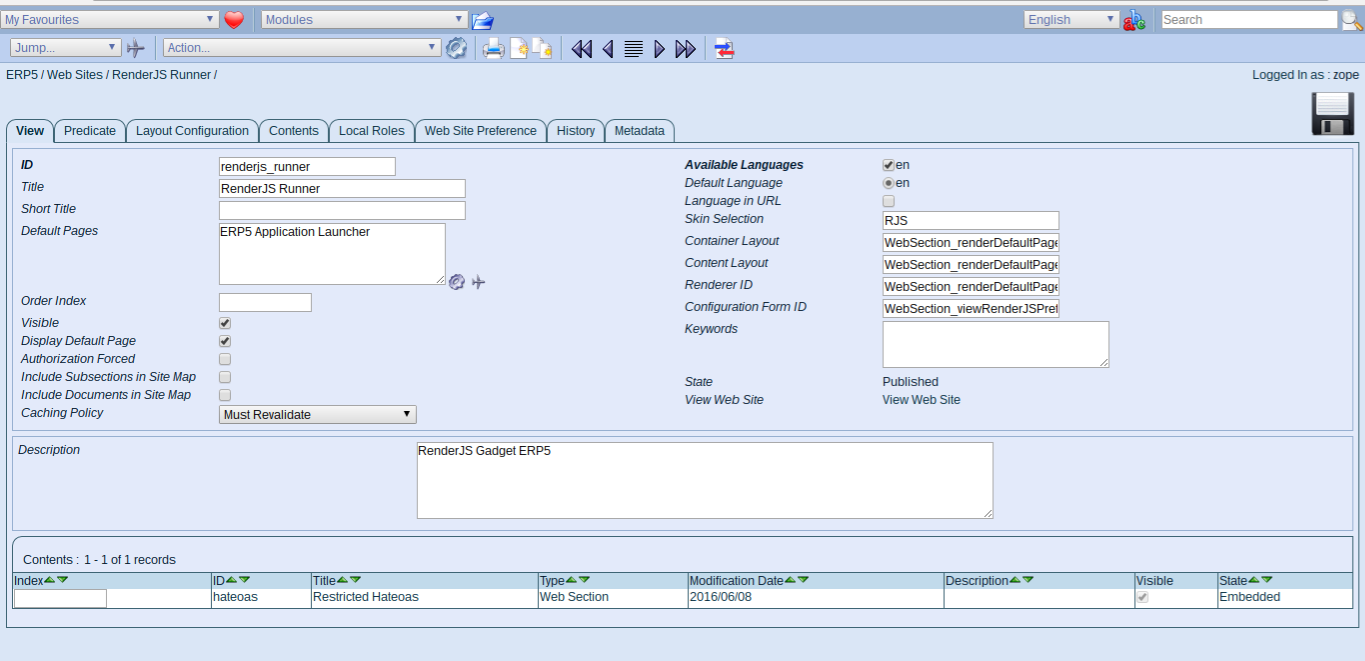
- Go back to renderjs_runner website
- Clone the website
Todo: Rename Website
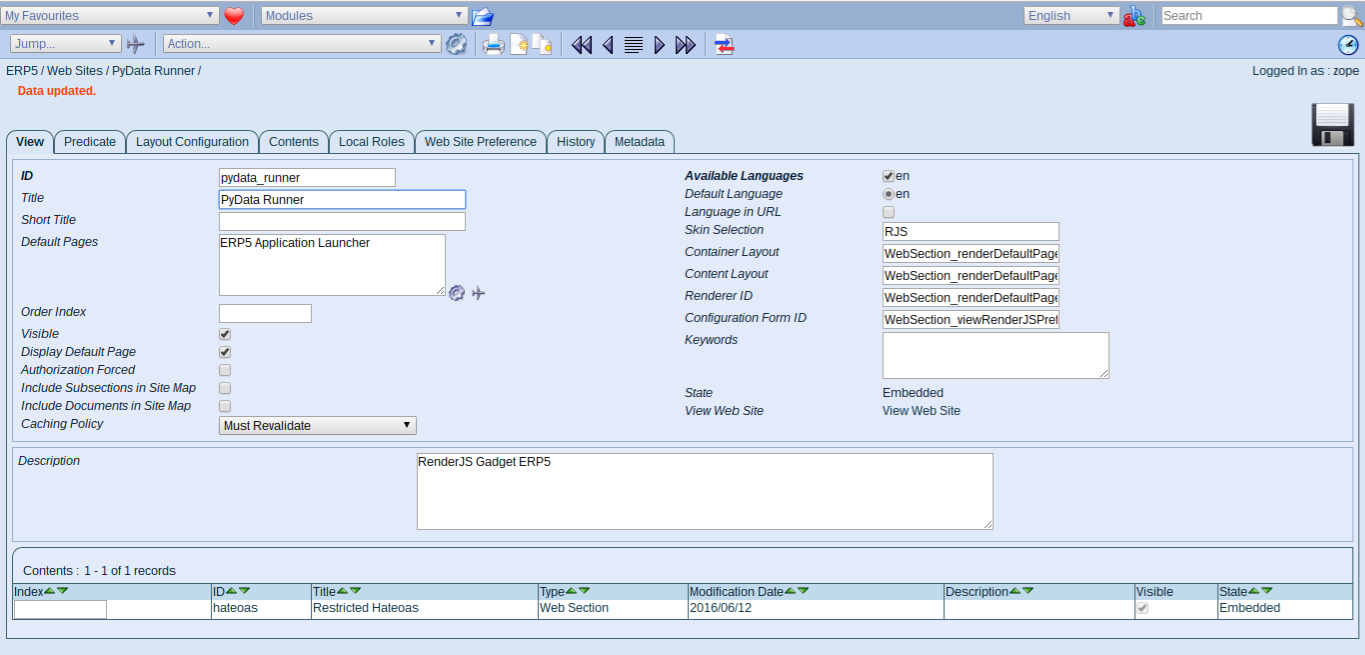
- Change id to pydata_runner
- Change name to PyData Runner
- Save
Todo: Publish Website
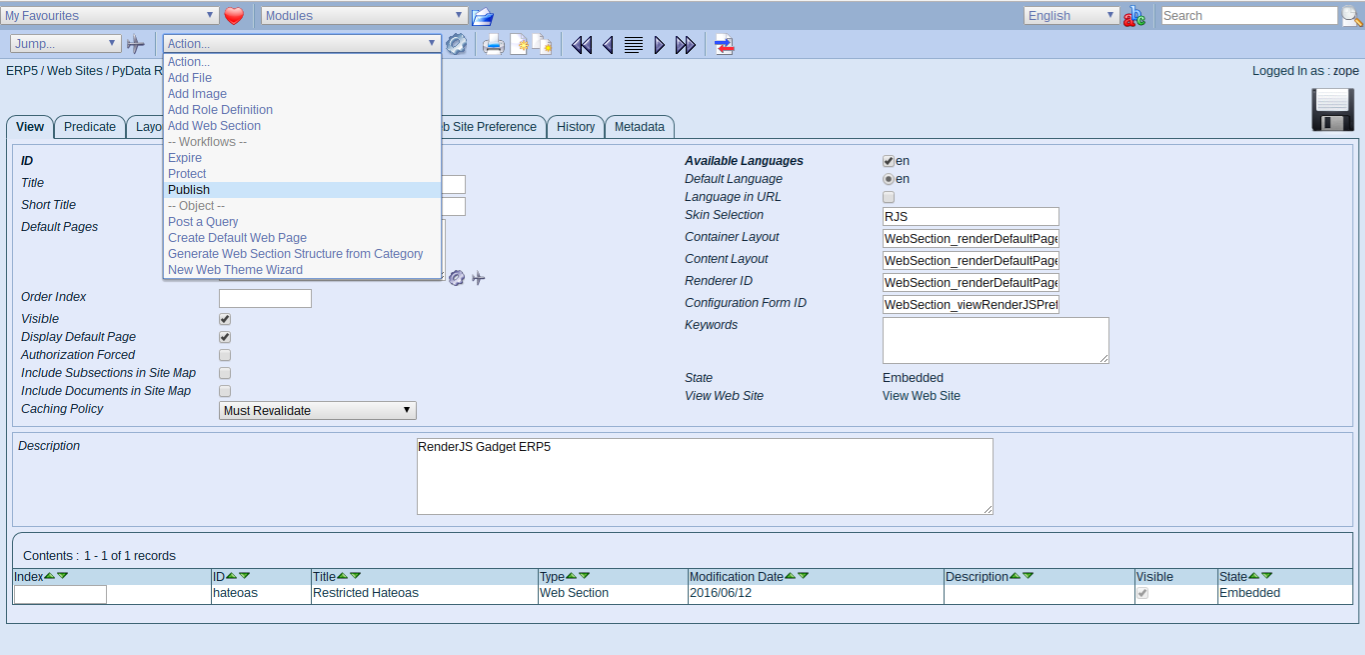
- Select action Publish and publish the site
- This changes object state from embedded to published
- Try to access:
http://softinstxxxx/erp5/web_site_module/pydata_runner/
- Wendelin/ERP5 usese workflows to change the state of objects
- A workflow in this case is to publish a webpage, which means changing its status from Embedded to Published
- Workflows (among other properties) can be security restricted. This concept applies to all documents in ERP5
Todo: Layout Properties

- Change to Tab "Layout Properties tab"
- Update the router to custom_gadget_erp5_router.html
- Refresh your app (disable cache), it will be broken, as this file doesn't exist
- The renderjs UI is also under development, the latest (unreleased) version supports the front pge gadget property
- We currently do a workaround, which also shows how to work with web pages in ERP5
- One advantage working with an aync promise-chain based framework like renderJS is the ability to capture errors
- It is possible to capture errors on client side, send report to ERP5 (stack-trace, browser) and not fail the app
- Much more fine-grainded control, we currently just dump to screen/console
Todo: Web Page Module
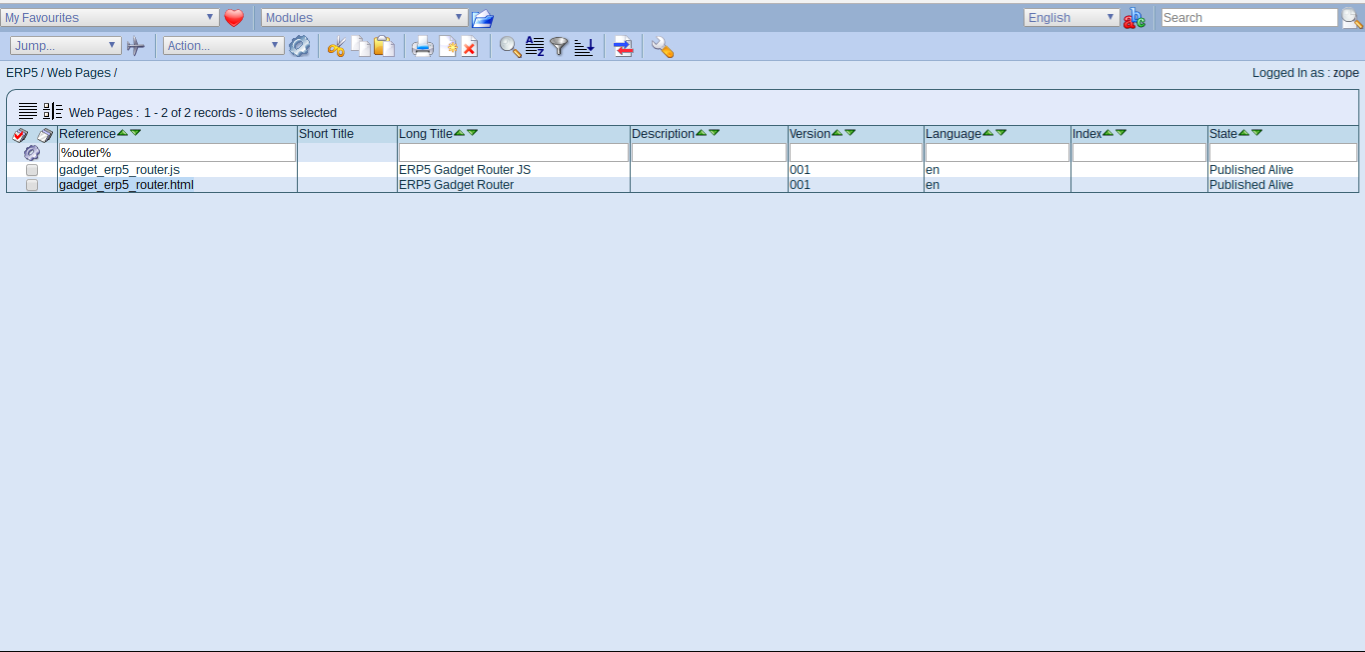
- Change to web page module
- Search for reference "router"
- The web page module includes html, js and css files used to build the frontend UI
- The usual way of working with static files is to clone a file, rename its reference and publish it alive (still editable)
Todo: Clone Web Pages
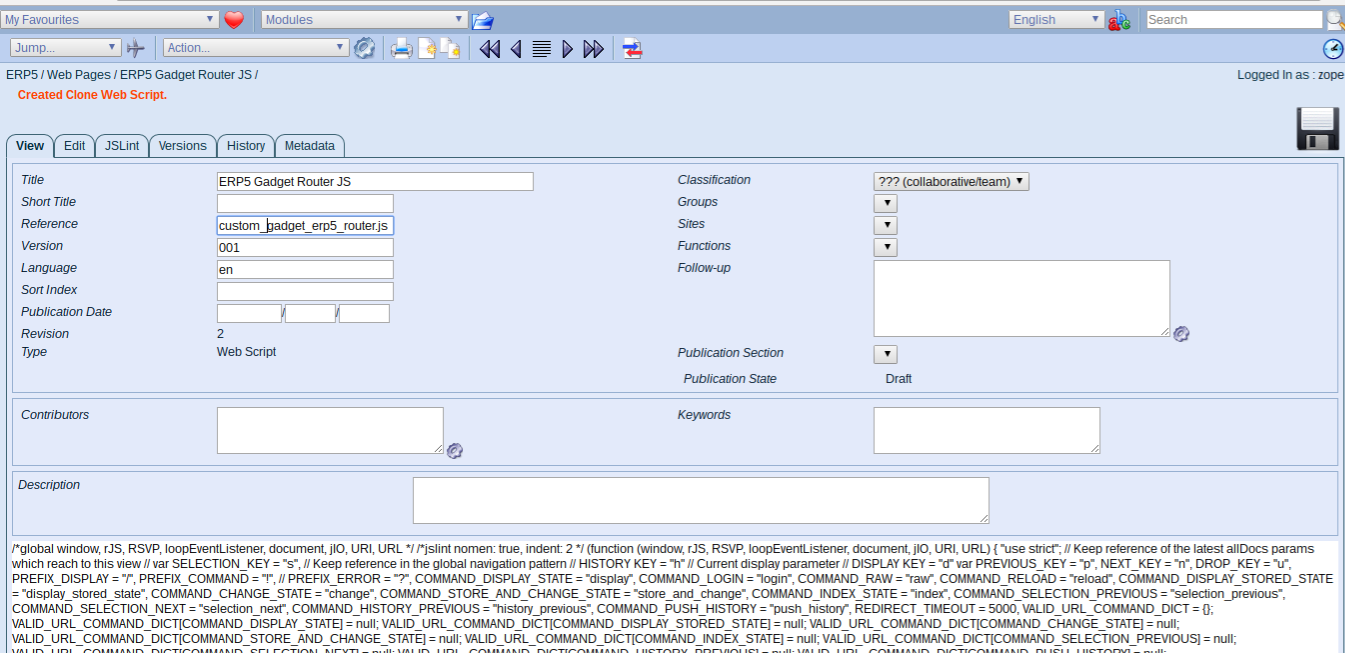
- Open both the html and javascript file in a new tab
- Clone both, prefix the references with custom_ and publish alive
- Click edit tab on the html page
Todo: Prefix JS file to display
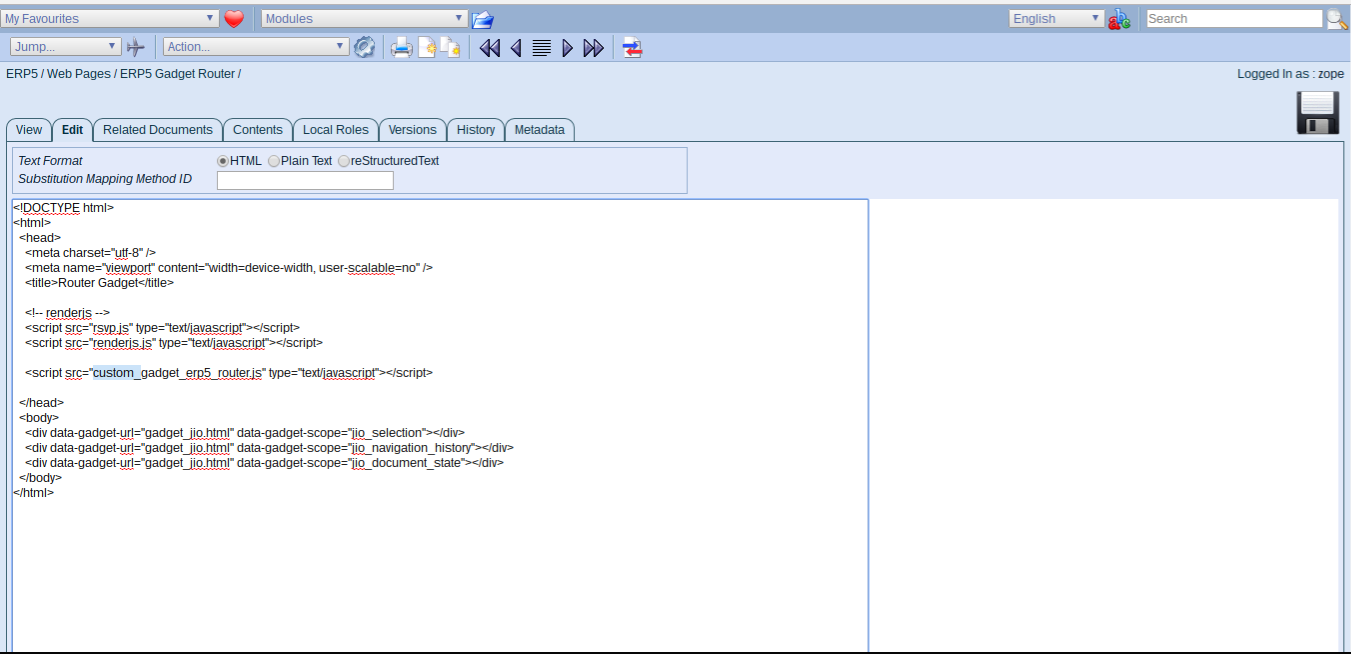
- Prefix the Javascript file to load to the correct reference
- Save, switch to the Javascript file in the other tab
- Click edit tab here as well
Todo: Update Default Gadget
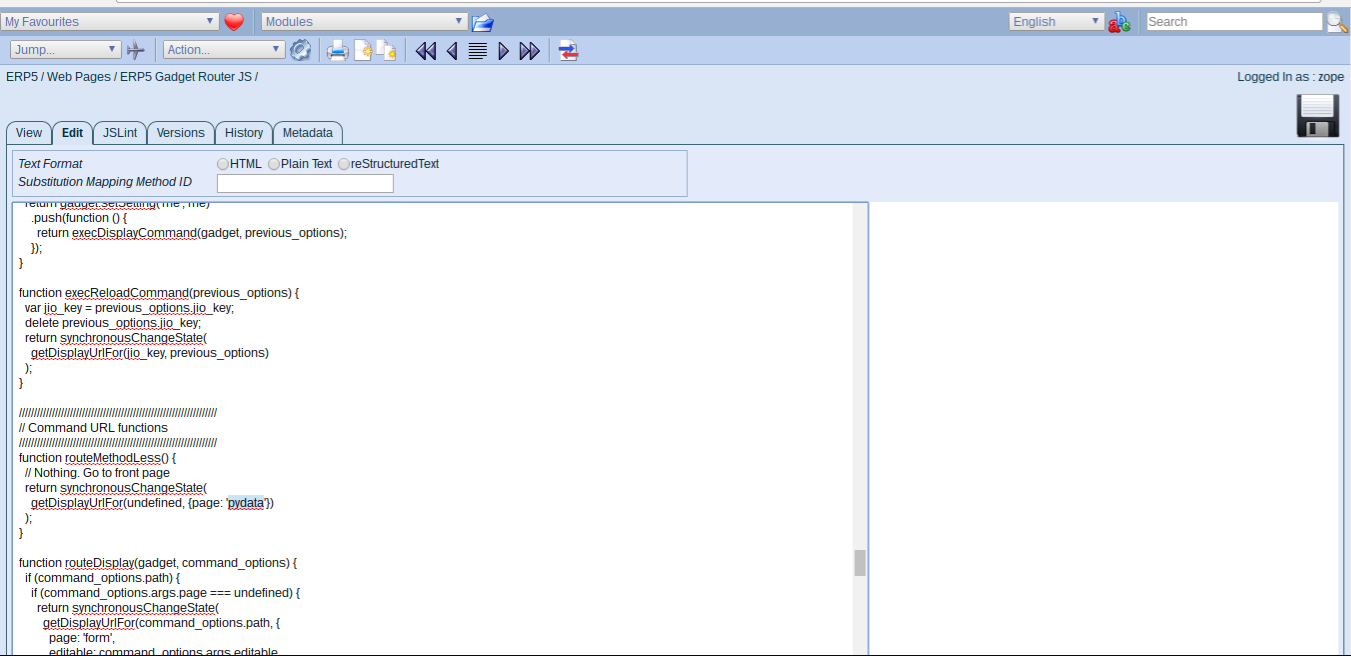
- Look for "worklist" and change it to "pydata"
- Save, we now have a new default gadget to load
- Go back to web page module
Todo: Clone Worklist gadgets
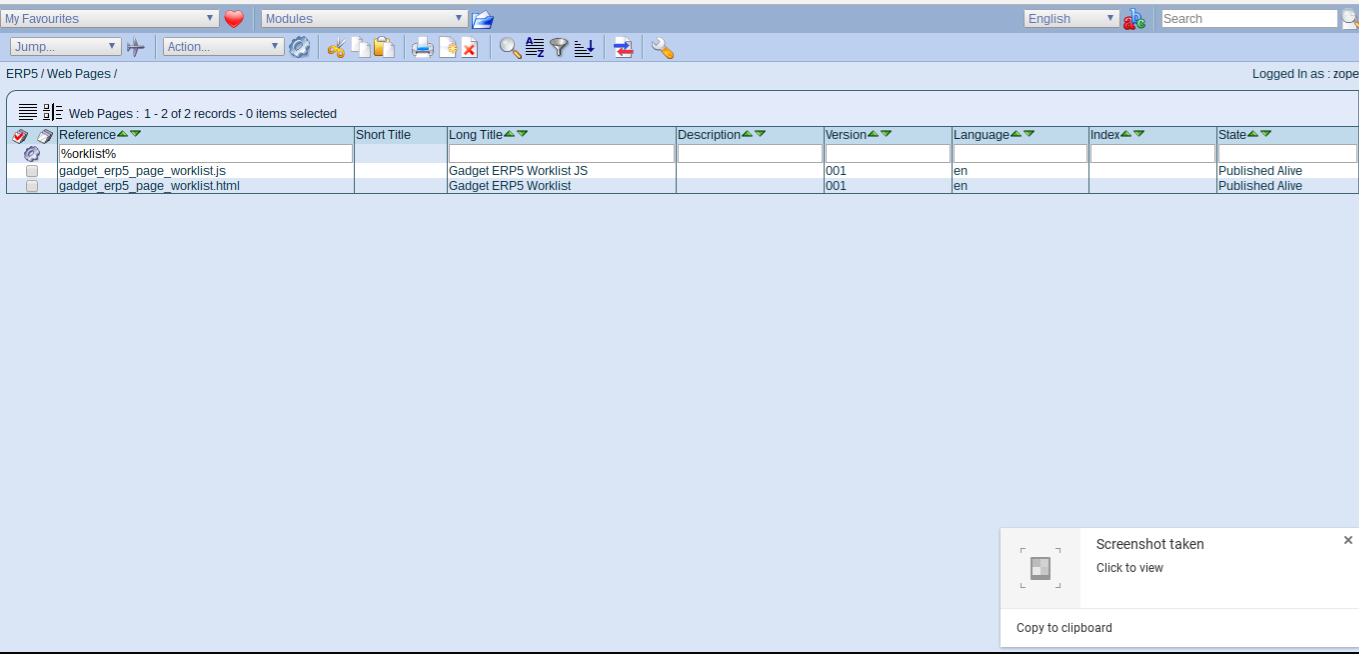
- Search for %worklist%, open both files in new tabs, clone, change title
- Replace "worklist" in references with "pydata", save and publish
- We will now edit both files to display our graph
Todo: Graph Gadget HTML (Gist)
<html>
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, user-scalable=no" />
<title>PyData Graph</title>
<script src="rsvp.js" type="text/javascript"></script>
<script src="renderjs.js" type="text/javascript"></script>
<script src="gadget_global.js" type="text/javascript"></script>
<script src="gadget_erp5_page_pydata.js" type="text/javascript"></script>
</head>
<body>
</body>
</html>
- This is a default gadget setup with some HTML.
- Gadgets should be self containable so they always include all dependencies
- RenderJS is using a custom version of RSVP for promises (we can cancel promises)
- The global gadget includes promisified event binding (single, infinite event listener)
Todo: Graph Gadget JS (Gist)
/*global window, rJS, RSVP, URI */
/*jslint nomen: true, indent: 2, maxerr: 3 */
(function (window, rJS, RSVP, URI) {
"use strict";
rJS(window)
// Init local properties
.ready(function (g) {
g.props = {};
})
// Assign the element to a variable
.ready(function (g) {
return g.getElement()
.push(function (element) {
g.props.element = element;
});
})
// Acquired methods
.declareAcquiredMethod("updateHeader", "updateHeader")
// declared methods
.declareMethod("render", function () {
var gadget = this;
return gadget.updateHeader({
page_title: 'PyData'
})
});
}(window, rJS, RSVP, URI));
Todo: Save, refresh web app
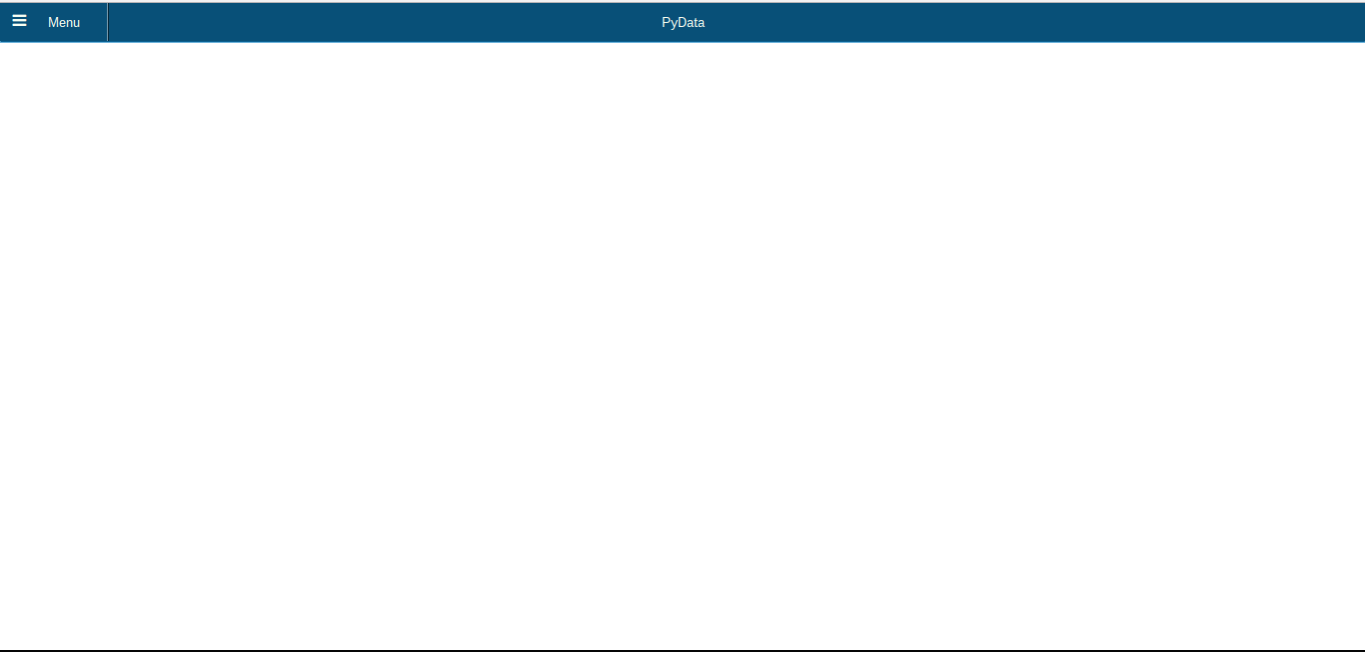
- Once you saved your files, go back to the web app and refresh
- You should now have a blank page with header set correctly
- We will now add fetch our graph and display it
Todo: Update Graph Gadget HTML (Gist)
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, user-scalable=no" />
<title>PyData Graph</title>
<!-- renderjs -->
<script src="rsvp.js" type="text/javascript"></script>
<script src="renderjs.js" type="text/javascript"></script>
<!-- custom script -->
<script src="dygraph.js" type="text/javascript"></script>
<script src="gadget_global.js" type="text/javascript"></script>
<script src="gadget_erp5_page_pydata.js" type="text/javascript"></script>
</head>
<body>
<div class="custom-grid-wrap">
<div class="custom-grid ui-corner-all ui-body-inherit ui-shadow ui-corner-all"></div>
</div>
<div data-gadget-url="gadget_ndarray.html"
data-gadget-scope="ndarray"
data-gadget-sandbox="public">
</div>
</body>
</html>
- Took from existing project, HTML was created to fit a responsive grid of graphs
- Added JS library for multidimensional arrays: NDArray
- Added JS libarary for displaying graphs: Dygraph
Todo: Graph Gadget JS (1) (Gist)
/*global window, rJS, console, RSVP, Dygraph */
/*jslint indent: 2, maxerr: 3 */
(function (rJS) {
"use strict";
var ARRAY_VALUE_LENGTH = 8,
OPTION_DICT = {
start_date: 0,
time_factor: 1000,
resolution: 1,
xlabel: 'x',
ylabel: 'y',
key_list: ["Channel 1", "Date"],
label_list: ["Date", "Channel 1"],
series_dict: {
"Channel 1": {
axis : "y",
color: "#00884B",
pointSize: 1,
visible : true,
connectSeparatedPoints: true
}
},
axis_dict: {
y: {position : "left", axisLabelColor: "grey", axisLabelWidth : 40, pixelsPerLabel : 30},
x: {drawAxis : true, axisLabelWidth : 60, axisLabelColor: "grey", pixelsPerLabel : 30}
},
connectSeparatedPoints: true
};
...
- First we only defined options for the Dygraph plugin
- In production system these are either set as defaults or stored along with respective data
Todo: Graph Gadget JS (2) (Gist)
function generateInitialGraphData(label_list) {
var i,
data = [[]];
for (i = 0; i < label_list.length; i += 1) {
data[0].push(0);
}
return data;
}
function convertDateColToDate(gadget, array) {
var label_list = gadget.property_dict.option_dict.label_list,
time_factor = gadget.property_dict.option_dict.time_factor,
time_offset = gadget.property_dict.option_dict.time_offset || 0,
i,
k;
for (k = 0; k < label_list.length; k += 1) {
if (label_list[k] === "Date") {
for (i = 0; i < array.length; i += 1) {
array[i] = [i, array[i]];
}
}
}
return array;
}
...
- Add methods outside of the promise chain
- Simplified (removed actual creation of date objects)
Todo: Graph Gadget JS (3) (Gist)
rJS(window)
.ready(function (gadget) {
gadget.property_dict = {};
return gadget.getElement()
.push(function (element) {
gadget.property_dict.element = element;
gadget.property_dict.option_dict = OPTION_DICT;
});
})
.declareAcquiredMethod("jio_getAttachment", "jio_getAttachment")
// render gadget
.declareMethod('render', function () {
var gadget = this,
interaction_model = Dygraph.Interaction.defaultModel,
option_dict = {},
url;
url = "http://softinstxxxx/erp5/web_site_module/pydata_runner/hateoas/data_array_module/[your_id]";
...
- "ready" triggered once gadget is loaded
- define gadget specific parameters
- "render" called by parent gadget or automatically
- we hardcode url parameter, by default it would be URL based
Todo: Graph Gadget JS (4) (Gist)
return new RSVP.Queue()
.push(function () {
return gadget.jio_getAttachment("erp5", url, {
start : 0,
format : "array_buffer"
});
})
.push(function (buffer) {
var array_length,
length,
array,
array_width = 1;
array_length = Math.floor(
buffer.byteLength / array_width / ARRAY_VALUE_LENGTH
);
length = buffer.byteLength - (buffer.byteLength % ARRAY_VALUE_LENGTH);
if (length === buffer.byteLength) {
array = new Float64Array(buffer);
} else {
array = new Float64Array(buffer, 0, length);
}
return nj.ndarray(array, [array_length, array_width]);
})
...
- Orchestrated process starting with a cancellable promise queue
- First step requesting the full file (NOT OUT-OF-CORE compliant - we load the whole file)
- Return file converted into ndarray
Todo: Graph Gadget JS (5) (Gist)
.push(function (result) {
var i,
data = [],
ndarray = result,
label_list = gadget.property_dict.option_dict.label_list,
key_list = gadget.property_dict.option_dict.key_list;
for (i = 1; i < label_list.length; i += 1) {
data = data.concat(
nj.unpack(
ndarray.pick(
null,
key_list.indexOf(label_list[i])
)
)
);
}
data = convertDateColToDate(gadget, data);
gadget.property_dict.data = data;
return gadget
});
})
.declareService(function () {
var gadget = this;
return gadget.property_dict.graph = new Dygraph(
gadget.property_dict.element,
gadget.property_dict.data,
gadget.property_dict.option_dict
);
});
}(rJS));
- Convert data into graph compatible format, store onto gadget
- "declareService" triggered once UI is built
- Graph will be rendered there.
Todo: Refresh Web Application
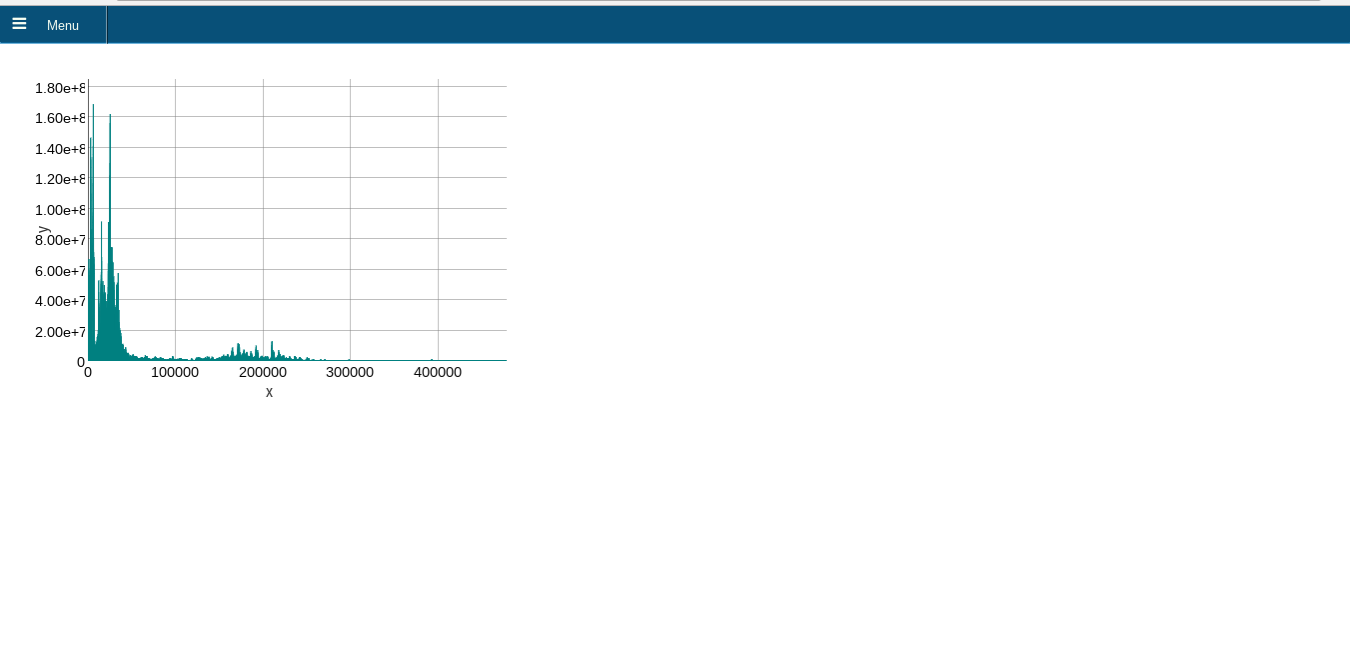
- Not out-of-core compliant, but jIO already allows to fetch ranges
- Example computes client-side as project requires to work offline "in the field"
- Ongoing process to fix libraries to work asynchronously and Big Data aware
Summary: Hyperconvergence?
 "
"
- Generic Hardware, specialized software services
- No more files, only services for compute, storage, networking, virtualization
- Manage through common toolset, scale by adding nodes
Summary: What did we do?
- SlapOS manages everything as a Service
- Including Deployment of VM Cluster, hosting of Audio Recording website
- Everything is a process